

flower
-
Posts
44 -
Joined
-
Last visited
Content Type
Forums
Store
Crowdfunding
Applications
Events
Raffles
Community Map
Posts posted by flower
-
-
if you just buy one 2.5GBe switch you can use only one interface and get more speed than with 2x1GBe
-
5 minutes ago, SR-G said:
What is the expected delay before having something stable for this NAS ?
Is it only worked on by KOBOL ?
How many people have a stable NAS versus an unstable NAS ?
Is my device faulty in any way ?
What is the refund policy on KOBOL ?
i gave up a few month ago.
however: i have a friend who is quite happy with his. omv/raid5 - nothing else.
i got mine somewhat stable by reducing cpu freq (same for min and max). but i do have huge stability requirements for my nas and also want it to run some services and so i have moved on.
sad for me. but i still think that there are good and working ones out there
-
1 hour ago, TDCroPower said:
how did you display this ingenious output?
apt install glances
it also has a web interface - but it is resource intensive
-
12 minutes ago, kirkusinnc said:
Subject: Question on disk usage
I completed my build of my Helios64 with 5 12tb WD drives in a Raid 5 array and got it up and running with only minor issues. (I had to manually install Open Media Vault as the box would appear to hang if I attempted to install using armbian-config. )
I've transferred over about 16TB of movies without issues and got Plex configured to use it. All is working well!
The one issue I've seen is the box hard drive lights will show lots of blinking and activity for several hours when there is nobody or no one accessing the box at all. If I reboot, the lights/activity start up as soon as it reboots. But, most of the time the lights are solid lit when there is no activity as I would expect.
Is there some kind of housekeeping being done periodically or other reason for the hard drives to be accessed?
Kirk
probably your array is still building. what does cat /proc/mdstat show you?
-
48 minutes ago, AurelianRQ said:
which Is a total mess and I guess I cannot use this connection.
you could get yourself a 2.5gbe switch (in case you need both connections, eg for a management net). they are not expensive anymore
-
2 minutes ago, dancgn said:
But, aren't that for nextcloud? I'm searching for a document Programm with full text search and ocr. I'm scanning the letters i'm recieving.
Also i'm fighting with an own bitwarden-Server for passwords.

oh sorry. i was confused and though you are talking about nc.
-
1 hour ago, dancgn said:
Hm, so I have to google a little bit. Thx
@flower
standard_init_linux.go:211: exec user process caused "exec format error"
This is what i get...
try this one: https://github.com/nextcloud/docker/tree/master/.examples/docker-compose/with-nginx-proxy-self-signed-ssl/mariadb/fpm
omgwtfssl doesnt work though. you have to do the cert stuff yourself.
here is my reverse proxy which handles certs: https://github.com/flower1024/proxy
(but you have to tweak it... it also does dyndns updates with spdyn.de and has a fixed Europe/Berlin Timezone. its not really built for sharing)
-
1 hour ago, dancgn said:
I understand, but there is no official docker image for arm64. So i tried it with armbian-config.
the official ones work with arm64 without any problems. only the reverse proxy doesnt.
-
1 hour ago, fromport said:
Have been testing my helios64 with 5x12TB drives in different setups.
omv & snapraid, but continuing a sync command uses so much ram that it become so slow that it might as well be described as unusable.
Next I tried omv & ZFS
Could get ZFS module compiled but then it wouldn't load the rest of utilities because missing dependencies (buster is real old)
So finally switched to try lizardfs. Crashed on me after a few hours, hooked up serial console.
Caught this error during the night: https://termbin.com/lsow
Is it easy to downgrade to 5.8.14 or even 4.x kernel ?
Downgrading and pinning is possible through armbian-config. it is described in the latest kobol blog (that page seems offline for me atm).
i used this to downgrade:
apt install \ linux-dtb-current-rockchip64=20.08.10 \ linux-headers-current-rockchip64=20.08.10 \ linux-image-current-rockchip64=20.08.10 \ armbian-firmware=20.08.10 \ linux-buster-root-current-helios64=20.08.10 \ linux-u-boot-helios64-current=20.08.10(but be carefull... next update would update them again)
afaik there is no way to go back to an 4.4 kernel. going from 4.4 to 5.8 is possible through armbian-config - but didnt work for me last time i tried
-
This afternoon (eg around 7h) i will put some smaller old disks in helios64 to keep an eye on the progress.
My point is just to collect as much info as possible on use cases that generate crash in order to prioritize focus.
I can start those containers there again.
If you want me to provide any additional info just tell me.
As it will sit there with test data only i can give you root access too in case you are interested.
Gesendet von meinem CLT-L29 mit Tapatalk
-
Yes it is tuned. Proxy buffers are very low (reverse proxy and fastcgi), mariadb and phpfpm.So you have tuned php-fpm, mariadb ? I haven't done extensive test of NC on Helios64, but I know that on Helios4 (with only 2GB RAM) i had to tune properly NC otherwise system will hangs (and reset because of watchdog). Not only because of OOM but also just too many thread / child process spawned overloading the system. I never tested NC in container though so maybe that doesn't apply to your use case. ( Just for reference :
https://docs.nextcloud.com/server/19/admin_manual/installation/server_tuning.html )
I never saw it above 1gb ram - except for linux file caches which touch zram swap after a while. But never filled it.
But what is your point about many processes? I do have many. Most of them are sleeping though. Do you think thats a problem?
Gesendet von meinem CLT-L29 mit Tapatalk
-
4 minutes ago, gprovost said:
Have you tuned your nextcloud install for a 4GB RAM system ?
Yes, all docker container and system together is around 1gb ram usage.
It uses zram after a while but that seems unrelated to that sync error.
I never saw my ram completely filled.
I dont use armbian nextcloud. I tweaked the mysql, redis, alpine variant which now runs stable on my old pc. Emby takes much ram there, but that container wasnt enabled on helios64.
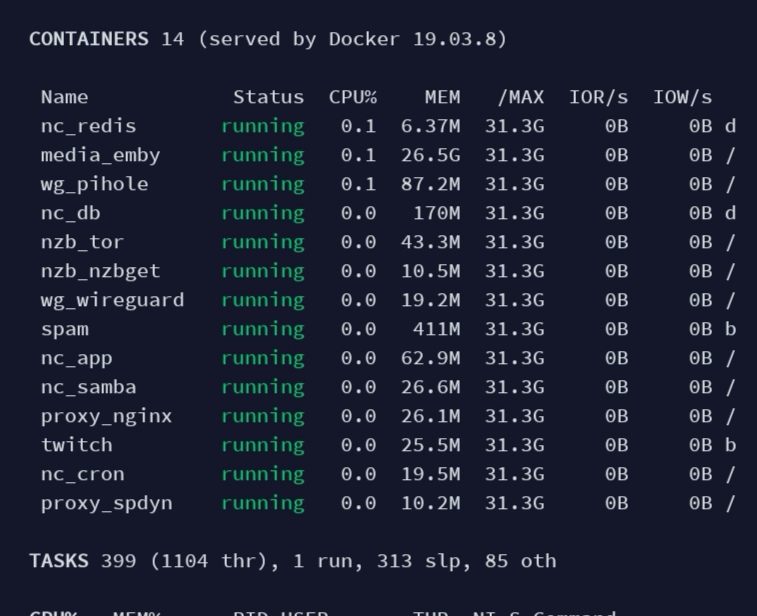
-
2 hours ago, gprovost said:
What page is broken ??
the original install instructions. yesterday morning it still was - now it is gone.
i wish for a litte bit more communication from your end. i still hope it will work out - and i still really like it. i am just frustrated.
regarding your question about tx offloading: i dont use omv and i have a script which disables them on every start.
but... something is wrong with networking on eth1 anyway. try syncing ~1tb with nextcloud. it wont work: even if the unit doesnt crash the nc client will disconnect multiple times and (even worse) you have to auth again (which is not typical for a disconnect)
my ssh connections are stable for hours though. not sure whats the problem there.
but.. does that imply that it is stable as long as you dont use 2.5GBe? that would be a good example where better communication would have helped.
-
Ok, folks its over
this unit was sold as a "high quality nas". i was expecting a little tweaking and some flaws but not those instabilites. they are just inaccable for a nas. a nas is about data integrity! and there is no filesystem which likes regular kernel locks. if kobol would sit in germany i would send it back.
i have migrated all disks and docker containers to an old i6900k i had lying around. i will have a look again in a few months.
btw: i even advertised and sold this unit to friends and would have continued to do so.
but: no official communication - and even your install page is broken since weeks - thats just too much.
sad
-
1 hour ago, Gareth Halfacree said:
Are there mitigations in the works for those speculative store bypass and SPECTRE v2 vulnerabilities?
not sure about arm but afaik they are already mitigated in linux. you may need to compile an own kernel.
i wouldnt though: as long as you dont plan to use your helios64 as a cloud hosting platform for customers or run untrusted code there is no need to do so. its not worth the performance impact.
-
Maybe its an ip conflict?Forgot to add ifconfig output, it might be useful
root@helios64:~# ifconfigeth0: flags=4163 mtu 1500 inet 192.168.0.110 netmask 255.255.255.0 broadcast 192.168.0.255 inet6 fe80::5550:854d:6ad0:b6d7 prefixlen 64 scopeid 0x20 ether 64:62:66:d0:03:7c txqueuelen 1000 (Ethernet) RX packets 390 bytes 60863 (59.4 KiB) RX errors 0 dropped 1 overruns 0 frame 0 TX packets 384 bytes 35588 (34.7 KiB) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0 device interrupt 27 eth1: flags=4099 mtu 1500 ether 64:62:66:d0:03:7d txqueuelen 1000 (Ethernet) RX packets 0 bytes 0 (0.0 RX errors 0 dropped 0 overruns 0 frame 0 TX packets 0 bytes 0 (0.0 TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0lo: flags=73 mtu 65536 inet 127.0.0.1 netmask 255.0.0.0 inet6 ::1 prefixlen 128 scopeid 0x10 loop txqueuelen 1000 (Local Loopback) RX packets 32 bytes 2640 (2.5 KiB) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 32 bytes 2640 (2.5 KiB) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
I also did further testing:- When pinging from my router, I get a timeout (set to 2000ms)
- When pinging my desktop and laptop computers from the Helios64, I get a response.
- When pinging its IP (192.168.0.110) from the Helios64, I get a response.
- When pinging the Helios from my desktop and laptop, I get a response.
apt-get install arp-scan
arp-scan --localnet -l
I didnt have any net problems with eth0 with any version.
Because of stability issues i am on kernel 5.8 armbian release .10 though
Gesendet von meinem CLT-L29 mit Tapatalk
-
i got this kernel exception while running iperf3 speed tests. helios64 did not crash though (i did a clean reboot)
cpu load is at 100% while sending or receiving (this is expected because of no tx offloading)
i have seen some connection drops with very long living connections (mutliple hours) maybe thats related.
one additional want to have: as i am not at home over weekends i'd love to see a feature that helios64 would auto restart on crash. i see the red led blinking.
that way my wireguard/pihole would continue working
[12403.586397] Hardware name: Helios64 (DT) [12403.586763] pstate: 00000005 (nzcv daif -PAN -UAO BTYPE=--) [12403.587273] pc : dev_watchdog+0x39c/0x3a8 [12403.587646] lr : dev_watchdog+0x39c/0x3a8 [12403.588014] sp : ffff800011abbd30 [12403.588321] x29: ffff800011abbd30 x28: ffff0000e7543e80 [12403.588808] x27: 0000000000000004 x26: 0000000000000140 [12403.589296] x25: 00000000ffffffff x24: 0000000000000002 [12403.589783] x23: ffff0000e6d703dc x22: ffff0000e6d70000 [12403.590270] x21: ffff0000e6d70480 x20: ffff800011807000 [12403.590757] x19: 0000000000000000 x18: 0000000000000000 [12403.591244] x17: 0000000000000000 x16: 0000000000000000 [12403.591730] x15: ffff80001182e000 x14: ffff800011a10242 [12403.592217] x13: 0000000000000000 x12: ffff800011a0f000 [12403.592705] x11: ffff80001182e000 x10: ffff800011a0f888 [12403.593192] x9 : 0000000000000000 x8 : 0000000000000006 [12403.593679] x7 : 0000000000000364 x6 : 0000000000000003 [12403.594166] x5 : 0000000000000000 x4 : 0000000000000000 [12403.594652] x3 : 0000000000000100 x2 : 0000000000000103 [12403.595138] x1 : b97470e46a7cb200 x0 : 0000000000000000 [12403.595626] Call trace: [12403.595861] dev_watchdog+0x39c/0x3a8 [12403.596206] call_timer_fn+0x30/0x1e0 [12403.596548] run_timer_softirq+0x1e0/0x5b0 [12403.596930] efi_header_end+0x16c/0x400 [12403.597287] irq_exit+0xc8/0xe0 [12403.597583] __handle_domain_irq+0x98/0x108 [12403.597971] gic_handle_irq+0x60/0x158 [12403.598319] el1_irq+0xb8/0x180 [12403.598615] arch_cpu_idle+0x28/0x218 [12403.598961] default_idle_call+0x1c/0x44 [12403.599326] do_idle+0x210/0x288 [12403.599629] cpu_startup_entry+0x24/0x68 [12403.599995] secondary_start_kernel+0x140/0x178 [12403.600410] ---[ end trace ad1687ba894eaefe ]--- [12403.600896] r8152 2-1.4:1.0 eth1: Tx timeout [12403.604757] xhci-hcd xhci-hcd.0.auto: bad transfer trb length 16754908 in event trb [12403.605617] r8152 2-1.4:1.0 eth1: Tx status -2 [12403.606197] xhci-hcd xhci-hcd.0.auto: bad transfer trb length 16754908 in event trb [12403.606964] r8152 2-1.4:1.0 eth1: Tx status -2 [12403.607640] r8152 2-1.4:1.0 eth1: Tx status -2 [12403.608300] r8152 2-1.4:1.0 eth1: Tx status -2 -
Sadly buster.13 is still unstable. Got this after a few hours without much load.
[ 8251.657645] ------------[ cut here ]------------
[ 8251.658075] kernel BUG at arch/arm64/kernel/traps.c:470!
[ 8251.658551] Internal error: Oops - BUG: 0 [#1] PREEMPT SMP
[ 8251.659038] Modules linked in: iptable_nat iptable_filter bpfilter wireguard libchacha20poly1305 poly1305_neon ip6_udp_tunnel udp_tunnel libblake2s libcurve25519_generic libblake2s_generic veth xt_nat xt_tcpudp xt_conntrack xt_MASQUERADE nf_conntrack_netlink xfrm_user xfrm_algo nft_counter xt_addrtype nft_compat nft_chain_nat nf_nat nf_conntrack nf_defrag_ipv6 nf_defrag_ipv4 nf_tables nfnetlink br_netfilter bridge governor_performance zstd zram r8152 snd_soc_hdmi_codec snd_soc_rockchip_i2s leds_pwm snd_soc_core panfrost pwm_fan gpio_charger hantro_vpu(C) gpu_sched snd_pcm_dmaengine snd_pcm rockchip_vdec(C) rockchip_rga v4l2_h264 snd_timer videobuf2_dma_sg videobuf2_dma_contig snd rockchipdrm v4l2_mem2mem dw_mipi_dsi videobuf2_vmalloc videobuf2_memops dw_hdmi videobuf2_v4l2 soundcore analogix_dp videobuf2_common drm_kms_helper cec rc_core videodev fusb30x(C) gpio_beeper mc drm drm_panel_orientation_quirks sg cpufreq_dt lm75 ip_tables x_tables autofs4 raid456 async_raid6_recov async_memcpy
[ 8251.659153] async_pq async_xor async_tx raid1 multipath linear raid10 raid0 md_mod realtek dwmac_rk stmmac_platform stmmac mdio_xpcs adc_keys
[ 8251.667928] CPU: 4 PID: 0 Comm: swapper/4 Tainted: G C 5.8.16-rockchip64 #20.08.13
[ 8251.668710] Hardware name: Helios64 (DT)
[ 8251.669062] pstate: 00000085 (nzcv daIf -PAN -UAO BTYPE=--)
[ 8251.669564] pc : do_undefinstr+0x2ec/0x310
[ 8251.669931] lr : do_undefinstr+0x1e0/0x310
[ 8251.670296] sp : ffff800011abbd50
[ 8251.670593] x29: ffff800011abbd50 x28: ffff0000f6ea5700
[ 8251.671067] x27: ffff0000f6ea5700 x26: ffff800011abc000
[ 8251.671540] x25: ffff8000114f1d20 x24: 0000000000000000
[ 8251.672012] x23: 0000000040000085 x22: ffff800010df6d90
[ 8251.672484] x21: ffff800011abbf00 x20: ffff0000f6ea5700
[ 8251.672956] x19: ffff800011abbdc0 x18: 0000000000000000
[ 8251.673428] x17: 0000000000000000 x16: 0000000000000000
[ 8251.673900] x15: 0000000000000006 x14: 00000d554264da40
[ 8251.674372] x13: 0000000000000322 x12: 000000000000036f
[ 8251.674844] x11: 0000000000000001 x10: 0000000000000004
[ 8251.675316] x9 : ffff0000f77a8590 x8 : ffff0000f77a7bc0
[ 8251.675788] x7 : ffff0000f6211dc0 x6 : ffff800011abbda8
[ 8251.676260] x5 : 00000000d5300000 x4 : ffff800011806118
[ 8251.676731] x3 : 0000000034000000 x2 : 0000000000000002
[ 8251.677203] x1 : ffff0000f6ea5700 x0 : 0000000040000085
[ 8251.677676] Call trace:
[ 8251.677900] do_undefinstr+0x2ec/0x310
[ 8251.678240] el1_sync_handler+0x88/0x110
[ 8251.678591] el1_sync+0x7c/0x100
[ 8251.678886] check_preemption_disabled+0x30/0x108
[ 8251.679305] __this_cpu_preempt_check+0x1c/0x34
[ 8251.679710] irq_exit+0x70/0xe0
[ 8251.679996] handle_IPI+0x25c/0x3e8
[ 8251.680312] gic_handle_irq+0x154/0x158
[ 8251.680655] el1_irq+0xb8/0x180
[ 8251.680938] arch_cpu_idle+0x28/0x218
[ 8251.681269] default_idle_call+0x1c/0x44
[ 8251.681622] do_idle+0x210/0x288
[ 8251.681912] cpu_startup_entry+0x28/0x68
[ 8251.682265] secondary_start_kernel+0x140/0x178
[ 8251.682673] Code: f9401bf7 17ffff7d a9025bf5 f9001bf7 (d4210000)
[ 8251.683223] ---[ end trace 47af1c5026823974 ]---
[ 8251.683636] Kernel panic - not syncing: Attempted to kill the idle task!
[ 8251.684232] SMP: stopping secondary CPUs
[ 8251.684588] Kernel Offset: disabled
[ 8251.684903] CPU features: 0x240022,2000600c
[ 8251.685275] Memory Limit: none
[ 8251.685562] ---[ end Kernel panic - not syncing: Attempted to kill the idle task! ]--- -
a short feedback to the latest versions:
.10 - most stable so far. three days without a problem
.11 - crashed once in 12h
.12 - crashed once in 12h
.13 - seems ok so far. running for 12h
with .13 i get these errors though (verbosity=6 in /boot/armbianEnv.txt, no rsyslog and systemd-journald redirected to serial):
[ 15.801564] systemd-udevd[466]: Process '/bin/ln -sf /sys/devices/platform/ff120000.i2c/i2c-2/2-004c/hwmon/hwmon2 /dev/thermal-board' failed with exit code 1. [ 15.804618] systemd-udevd[491]: Process '/bin/ln -sf /sys/devices/virtual/thermal/thermal_zone0/hwmon0 /dev/thermal-cpu' failed with exit code 1.
-
1 hour ago, dancgn said:
Today, home from doing stuff with my kids, the server won't work. No connection with ssh or serial.
After restart the server runs about 3-4 Minutes and then this messages was shown:
https://www.directupload.net/file/d/5977/5duv2mqg_png.htm
https://www.directupload.net/file/d/5977/jhn6v7wz_png.htm
I completley reinstalled the server, but the problem stayed. Rebooting everytime without doing something. And the startup (Starting kernel ...) needs a lot of time.
Help...
Greets
Daniel
-> My german is much better...
it is easier to read logfiles. in putty under logging you can define where to write it.
---
Halloo/
Ich schreibe auch lieber auf Deutsch xD Am besten mal unter putty das Logging einschalten. Mit den Dateien kann man dann mehr anfangen.
-
11 minutes ago, raoulh said:
My machine is connected with a 10G SFP+ and is working great with other 10G devices I have on my network.
What todes ethtool eth1 show?
root@ghost:~# ethtool eth1 Settings for eth1: Supported ports: [ MII ] Supported link modes: 10baseT/Half 10baseT/Full 100baseT/Half 100baseT/Full 1000baseT/Full 2500baseT/Full Supported pause frame use: No Supports auto-negotiation: Yes Supported FEC modes: Not reported Advertised link modes: 10baseT/Half 10baseT/Full 100baseT/Half 100baseT/Full 1000baseT/Full 2500baseT/Full Advertised pause frame use: Symmetric Receive-only Advertised auto-negotiation: Yes Advertised FEC modes: Not reported Link partner advertised link modes: 100baseT/Half 100baseT/Full 1000baseT/Full Link partner advertised pause frame use: No Link partner advertised auto-negotiation: Yes Link partner advertised FEC modes: Not reported Speed: 2500Mb/s Duplex: Full Port: MII PHYAD: 32 Transceiver: internal Auto-negotiation: on Supports Wake-on: pumbg Wake-on: g Current message level: 0x00007fff (32767) drv probe link timer ifdown ifup rx_err tx_err tx_queued intr tx_done rx_status pktdata hw wol Link detected: yesthe important part is: "Speed: 2500MB/s"
my iperf3 shows 1.8GBit/s
it is possible that your switch doesnt support 2.5Gbe. Could you post vendor and model?
-
1 hour ago, Borromini said:
@flower and @barnumbirr Which Noctua fans did you get?
Also curious if anyone has installed a dust filter behind the front grille.
Thanks!
80mm 2200rpm pwm
No i dont have a dust filter.
This one https://www.heise.de/preisvergleich/noctua-nf-a8-pwm-a1165563.html
-
For reference: this is my test on 2.5Gbe. One switch. helios64 has much load atm though.
tx and rx offloading is off
Server listening on 9999 ----------------------------------------------------------- Accepted connection from 192.168.178.10, port 47294 [ 5] local 192.168.178.2 port 9999 connected to 192.168.178.10 port 47296 [ ID] Interval Transfer Bitrate [ 5] 0.00-1.00 sec 211 MBytes 1.77 Gbits/sec [ 5] 1.00-2.00 sec 190 MBytes 1.60 Gbits/sec [ 5] 2.00-3.00 sec 220 MBytes 1.85 Gbits/sec [ 5] 3.00-4.00 sec 167 MBytes 1.40 Gbits/sec [ 5] 4.00-5.00 sec 226 MBytes 1.89 Gbits/sec [ 5] 5.00-6.00 sec 211 MBytes 1.77 Gbits/sec [ 5] 6.00-7.00 sec 217 MBytes 1.82 Gbits/sec [ 5] 7.00-8.00 sec 201 MBytes 1.69 Gbits/sec [ 5] 8.00-9.00 sec 271 MBytes 2.28 Gbits/sec [ 5] 9.00-10.00 sec 215 MBytes 1.81 Gbits/sec [ 5] 10.00-10.00 sec 256 KBytes 1.25 Gbits/sec - - - - - - - - - - - - - - - - - - - - - - - - - [ ID] Interval Transfer Bitrate [ 5] 0.00-10.00 sec 2.08 GBytes 1.79 Gbits/sec receiver -
18 minutes ago, gprovost said:
We will do an announcement soon but we realized we made a design mistake on the Helios64 2.5GbE port (LAN2 | eth1) which makes it not perform well in 1000Mb/s mode, however no impact in 2500baseT mode.
Does this mean i can enable tx offloading again?
It is connected to a 2.5gbe switch
Helios64 - freeze whatever the kernel is.
in Rockchip
Posted
Afaik the problem is that there simply isn't enough power.
I (and my friend) just have given up and bought ryzen