

djurny
-
Posts
66 -
Joined
-
Last visited
Content Type
Forums
Store
Crowdfunding
Applications
Events
Raffles
Community Map
Posts posted by djurny
-
-
On 4/23/2019 at 11:48 AM, gprovost said:
@djurny Ok thanks, keep us updated.
Hi,
Yesterday evening, the second box froze up again. This time I had the other PSU connected, to rule out any PSU failure.
Time CPU load %cpu %sys %usr %nice %io %irq CPU C.St. 23:40:16: 1600MHz 0.10 5% 2% 0% 0% 2% 0% 67.5째C 0/0 23:40:21: 1600MHz 0.09 15% 6% 0% 3% 3% 1% 68.0째C 0/0 23:40:26: 1600MHz 0.09 7% 2% 0% 0% 1% 1% 67.5째C 0/0 23:40:31: 800MHz 0.16 13% 6% 0% 4% 2% 0% 67.0째C 0/0 23:40:36: 1600MHz 0.23 6% 2% 0% 1% 2% 0% 68.0째C 0/0 23:40:41: 1600MHz 0.21 14% 6% 0% 3% 3% 0% 67.5째C 0/0 23:40:47: 1600MHz 0.19 6% 2% 0% 1% 1% 0% 67.5째C 0/0Same symptoms.
First box is still going strong after the PSU swap:
11:37:11 up 3 days, 14:18, 8 users, load average: 1.43, 1.55, 1.60Groetjes,
-
8 hours ago, gprovost said:
@djurny We not sure what it could be. BTW is it a system from batch1 or batch2 ? We are asking because if it's batch2 and as you said the fan still spin after system has hanged, then it means PWM it is running, so the system is not completely hang. In order to narrow down the issue, could you swap the PSUs between your 2 Helios4 systems, to see if it could be a faulty PSU ? In any case, if we can't figure out the root cause, then we will proceed to a replacement of the board.
Hi,
They are both from batch #2. I will check try and swap the PSU with the other box over the weekend and indeed see if it still happens.
Thanks,
Groetjes,
-
Bad news... It took almost over a week, but: My 2nd box froze today, last output on the serial console:
17:41:22: 800MHz 0.19 10% 2% 0% 1% 5% 0% 67.0°C 0/0 Time CPU load %cpu %sys %usr %nice %io %irq CPU C.St. 17:41:28: 1600MHz 0.17 14% 6% 0% 4% 3% 1% 67.5°C 0/0 17:41:33: 800MHz 0.16 6% 2% 0% 1% 1% 0% 67.0°C 0/0 17:41:38: 1600MHz 0.31 15% 6% 0% 3% 2% 1% 67.5°C 0/0 17:41:43: 1600MHz 0.36 7% 2% 0% 1% 2% 1% 68.0°C 0/0 17:41:48: 1600MHz 0.33 15% 6% 0% 5% 1% 0% 67.5°C 0/0 17:41:53: 1600MHz 0.31 6% 2% 0% 1% 1% 0% 68.5°C 0/0Same symptoms, NIC is blinking, heartbeat LED is off, serial console is unresponsive.
Any thoughts?
Groetjes,
-
6 hours ago, gprovost said:
@djurny Yeah normally kernel message should be output to serial. Well let us know if you catch anything with your monitoring setup.
BTW which HDD models are using ? Do you have USB devices connected ? I'm wondering if it could a power rail issue.
Hi,
Box #0 (4x WD Red 4TB):
- /dev/sda 30 WDC WD40EFRX-68N32N0 WD-WCC7K1KS6EUY
- /dev/sdb 32 WDC WD40EFRX-68N32N0 WD-WCC7K2KCR8J9
- /dev/sdc 31 WDC WD40EFRX-68N32N0 WD-WCC7K1RVY70H
-
/dev/sdd 31 WDC WD40EFRX-68N32N0 WD-WCC7K6FE2Y7D
Box #1 (4x WD Blue 2TB):
- /dev/sda 32 WDC WD20EZRZ-00Z5HB0 WD-WCC4M2VFJPP7
- /dev/sdb 31 WDC WD20EZRZ-00Z5HB0 WD-WCC4M0JNZ8EX
- /dev/sdc 31 WDC WD20EZRZ-00Z5HB0 WD-WCC4M6HPXZFZ
- /dev/sdd 29 WDC WD20EZRZ-00Z5HB0 WD-WCC4M6HPX4AP
No other devices connected to either box. The 2nd colum is HDD reported temperature in Celcius, it's always around 30~35.
SpoilerI've sligthly modified fancontrol to link the top fan (-j10) to maintain the average HDD temperature around between 30~45 Celcius. Bottom fan (-j17) is linked to CPU temperature (/dev/thermal-cpu/temp1_input).
Groetjes,
-
On 9/18/2018 at 7:20 PM, gprovost said:
@nemo19 Sorry to hear that now you are facing some other instability with the board. Please next time it occurs, can you send me your syslog files along the link generated by armbianmonitor -u
Hi,
My second Helios4 box also randomly hangs/stalls at unexpected times. It does not seem load-dependent, as today it stalled while the system was not doing anything (all load intensive tasks are running overnight).
The Helios4 boxen are both connected to a Raspberry Pi2b via USB/serial console to check if anything odd had happened, but unfortunately, the serial console of the stalled box always shows nothing but the login prompt. No oops, no "bug on" or any other "error" message.
Symptoms:
- The heartbeat LED stops blinking.
- NIC LEDs are still show activity.
- Fans remain on constant speed, not regulated anymore.
- Serial console is unresponsive.
- /var/log/* and /var/log.hdd/* shows nothing out of the ordinary - the logging just stops at some point. Most likely armbian-ramlog prevents the interesting bits from being flushed to /var/log.hdd/...
I will now watch (a customized) sensors + armbianmonitor -m the serial console. Also, disable armbian-ramlog for now.
Do you have any idea what else I can redirect to serial console periodically to check if anything out of the ordinary is happening?
Groetjes,
-
@gprovost, indeed /proc/irq/${IRQ}/smp_affinity. What I saw irqbalance do is perform a one-shot assignment of all IRQs to CPU1 (from CPU0) and then...basically nothing. The "cpu mask" shown by irqbalance is '2', which lead me to the assumption that it is not taking CPU0 into account as a CPU it can use for the actual balancing. So all are "balanced" to one CPU only.
Overall, the logic for the IRQ assignment spread over the two CPU cores was: When CPU1 is handling ALL incoming IRQs, for both SATA, XOR and CESA for all disks in a [software] RAID setup, then CPU1 will be the bottleneck of all transactions. The benefit of the one-shot 'balancing' is that you don't really need to worry about the ongoing possible IRQ handler migration from CPUx to CPUy, as the same CPU will handle the same IRQ all the time, no need to migrate anything from CPUx to CPUy continuously.
Any further down the rabbit hole would require me to go back to my college textbooks
 .
.
Groetjes,
-
L.S.,
A quick update on the anecdotal performance of LUKS2 over LUKS;
md5sum'ing ~1 TiB of datafiles on LUKS:
avg-cpu: %user %nice %system %iowait %steal %idle 0.15 20.01 59.48 2.60 0.00 17.76 Device: tps MB_read/s MB_wrtn/s MB_read MB_wrtn sdb 339.20 84.80 0.00 848 0 dm-2 339.20 84.80 0.00 848 0md5sum'ing ~1 TiB of datafiles on LUKS2:
avg-cpu: %user %nice %system %iowait %steal %idle 0.05 32.37 36.32 0.75 0.00 30.52 Device: tps MB_read/s MB_wrtn/s MB_read MB_wrtn sdd 532.70 133.18 0.00 1331 0 dm-0 532.80 133.20 0.00 1332 0sdb:
-
sdb1 optimally aligned using parted.
- LUKS(1) w/aes-cbc-essiv:256, w/256 bit key size.
- XFS with 4096 Bytes sector size.
- xfs_fsr'd regularly, negligible file fragmentation.
sdd:
-
sdd1 optimally aligned using parted.
- LUKS2 w/aes-cbc-essiv:256, w/256 bit key size and w/4096 Bytes sector size, as @matzman666 suggested.
- XFS with 4096 Bytes sector size.
Content-wise: sdd1 is a file-based copy of sdb1 (about to wrap up the migration from LUKS(1) to LUKS2).
Overall a very nice improvement!
Groetjes,
p.s. Not sure if it added to the performance, but I also spread out the IRQ assignments over both CPUs, making sure that each CESA and XOR engine have their own CPU. Originally I saw that all IRQs are handled by the one and same CPU. For reasons yet unclear, irqbalance refused to dynamically reallocate the IRQs over the CPUs. Perhaps the algorithm used by irqbalance does not apply well to ARM or the Armada SoC (- initial assumption is something with cpumask being reported as '00000002' causing irqbalance to only balance on- and to CPU1?).
-
sdb1 optimally aligned using parted.
-
- edit -
How my skepticism (read: incredulity and conceit) can put me on my wrong foot sometimes
 .
.
Updated to the latest version of systemd (and ancillaries) yesterday and this has fixed both ssh ('/var/run/sshd' missing) and GNU screen ('Cannot make directory '/var/run/screen': Permission denied') issues on my OrangePi Zero setup: ** 229-4ubuntu21.16
Groetjes,
SpoilerHi, I'm having the same recurring issue with the ssh service failing to startup as well on my OrangePi Zero.
After lots of tinkering I found out that '/var/run' and/or '/run' was overlayed by a 'tmpfs' after/during the tmpfiles service was started. This caused the tmpfiles service to use a inode for /var/run or /run that wasn't accessible anymore due to the tmpfs overlay on '/run' or '/var/run'. (Details are lost on me, as this was quite some time ago already.)
I modified the ssh service configuration to have ssh wait on the tmpfiles-setup service - see Spoiler below. The fixup worked for a while, but after a reboot over the holidays (lots of aptitude update+upgrades before the reboot), it appears that it's back to non-operational. Quite annoying, as it's a headless board.
Perhaps the Spoiler below might also work for some people, as soon as I have a configuration change working, I'll share that here as well. Next search is to figure out when and by who the tmpfs overlay is done for /run and /var/run.I prefer to fix the configuration to get the ssh service to work and keep up-to-date with all packages in the meantime.
Comments are welcome by the way,
Groetjes,p.s. For all spoilers and fixups in this reply, use at your own risk and make sure you have backups of all files that you choose to modify. Also make sure that you have an alternative login method other than ssh to mend any typos or other collateral damage that might follow.
Spoiler--- ssh.service 2018-12-01 21:40:36.728028572 +0800 +++ ssh.service.fixup 2018-12-01 21:41:50.837422407 +0800 @@ -1,6 +1,8 @@ [Unit] Description=OpenBSD Secure Shell server -After=network.target auditd.service +#[begin] Ansible Managed: Add dependency on tmpfiles-setup +After=network.target auditd.service systemd-tmpfiles-setup.service +#[end] Ansible Managed: Add dependency on tmpfiles-setup ConditionPathExists=!/etc/ssh/sshd_not_to_be_run [Service]Spoiler above can be applied with GNU 'patch', on '/lib/systemd/system/ssh.service'. systemd needs a 'systemctl deamon-reload' after changing the service configuration, as the dependencies have changed.
SpoilerSpoiler below is not in unified diff format and has to be applied to '/lib/systemd/system/systemd-tmpfiles-setup.service' manually.
[Unit] Description=Create Volatile Files and Directories Documentation=man:tmpfiles.d(5) man:systemd-tmpfiles(8) DefaultDependencies=no Conflicts=shutdown.target After=local-fs.target systemd-sysusers.service #[disabled] Before=sysinit.target shutdown.target #[begin] Before=sysinit.target shutdown.target sshd.service #[end] RefuseManualStop=yes
-
6 hours ago, aprayoga said:
@djurny Thanks to bring this up to us.
Apparently we missed CONFIG_ASYNC_TX_DMA=y in kernel configuration during the transition from mvebu-default (LK 4.4) to mvebu-next (LK 4.1x).After enabling, recompile the kernel and creating new 8GB array (RAID 5, 3x 4GB), here is what i got
46: 483063 0 GIC-0 54 Level f1060800.xor 47: 554757 0 GIC-0 97 Level f1060900.xor
You can find the kernel on our repo.
We did some test and found no difference in term of CPU load and performance. We still investigating how to take advantage of MV_XOR to improve perf and/or system load.
Hi,
Eager to test out the new linux-4.14.94-mvebu kernel, but I'm having some boot issues with it; SDcard refuses to be detected by the kernel:
<snip> [ 1.657831] Key type encrypted registered [ 1.658709] USB-PWR: supplied by power_brick_12V [ 1.739202] mmc0: error -110 whilst initialising SD card [ 1.860846] ata1: SATA link down (SStatus 0 SControl 300) [ 1.861044] ata2: SATA link down (SStatus 0 SControl 300) <snip>
Hopefully it's just the SDcard itself being broken. (Although it's a 4 weeks old branded one.)
I'll give an update once I get my box going.
-[ update ]-
SDcard is fine. There is something NOK with the new image/headers/dtb. After hacking it back to 4.14.92-mvebu all was fine again.
I still want to test this, but I'm not sure what is causing the mmc driver from not detecting my SDcard? Do I need to update/install more than just image, headers and dtb packages?
-[ edit ]-
Also, do note that during 4.14.94-mvebu kernel boot, both modules mentioned before are still opting for SW methods instead of using the xor engines. It looks like mv_xor initialization/publishing is still done after the benchmark & selection is done by crypto/async_tx & raid6?
Thanks,
Groetjes,
-
On 2/21/2018 at 6:18 AM, gprovost said:
In regards to XOR engine :
Check your kernel message you should see the kernel has detected 2 XOR engines.
[ 0.737452] mv_xor f1060800.xor: Marvell shared XOR driver [ 0.776401] mv_xor f1060800.xor: Marvell XOR (Descriptor Mode): ( xor cpy intr pq ) [ 0.776570] mv_xor f1060900.xor: Marvell shared XOR driver [ 0.816397] mv_xor f1060900.xor: Marvell XOR (Descriptor Mode): ( xor cpy intr pq )
In the current mvebu kernel configs, mv_xor driver is part of the kernel, not a module.
But I agree there is no obvious way to say if the system offload on the hardware XOR engine.
Hi,
I'm building my second box and was going for a mdadm RAID setup there. After doing some throughput tests, I found that the mv_xor unit is not used when accessing data on a RAID array (in my case I'm trying RAID6 for now).
It's indeed a kernel builtin, but it looks like it's initialized after the other builtins are initialized.
Dec 14 08:56:44 localhost kernel: [ 0.004541] xor: measuring software checksum speed Dec 14 08:56:44 localhost kernel: [ 0.043886] arm4regs : 2534.000 MB/sec <...> Dec 14 08:56:44 localhost kernel: [ 0.163886] xor: using function: arm4regs (2534.000 MB/sec) <snip> Dec 14 08:56:44 localhost kernel: [ 0.239983] raid6: int32x1 gen() 270 MB/s <...> <...> Dec 14 08:56:44 localhost kernel: [ 1.259902] raid6: neonx8 xor() 1041 MB/s Dec 14 08:56:44 localhost kernel: [ 1.259904] raid6: using algorithm neonx4 gen() 1349 MB/s Dec 14 08:56:44 localhost kernel: [ 1.259906] raid6: .... xor() 1377 MB/s, rmw enabled Dec 14 08:56:44 localhost kernel: [ 1.259908] raid6: using neon recovery algorithm <snip> Dec 14 08:56:44 localhost kernel: [ 1.425179] mv_xor f1060800.xor: Marvell shared XOR driver Dec 14 08:56:44 localhost kernel: [ 1.461595] mv_xor f1060800.xor: Marvell XOR (Descriptor Mode): ( xor cpy intr ) Dec 14 08:56:44 localhost kernel: [ 1.461694] mv_xor f1060900.xor: Marvell shared XOR driver Dec 14 08:56:44 localhost kernel: [ 1.493578] mv_xor f1060900.xor: Marvell XOR (Descriptor Mode): ( xor cpy intr )
The previous builtins do benchmarking without seeing the mv_xor modules and both choose a SW method for xor'ing.
This is also evident by checking if the xor units produce any IRQs during writing to RAID array: almost no IRQs for either xor module:
46: 2 0 GIC-0 54 Level f1060800.xor 47: 2 0 GIC-0 97 Level f1060900.xorUnfortunately, I don't have the time to deep-dive into this, but from previous experience with building kernels and doing some optimizations with changing initialization order of kernel builtins, it would help if this module is linked before both 'crypto/async_tx' and 'raid6' (not sure about the latter builtin/module name) - Link order determines the initialization order for builtin kernel modules.
Where to address this?
Groetjes,
-
@matzman666 Sorry, no measurements. From memory the numbers for raw read performance were way above 100MB/sec according to 'hdparm -t'. Currently my box is live, so no more testing with empty FSes on unencrypted devices for now. Perhaps someone else can help out?
-[ edit ]-
So my 2nd box is alive. The setup is slightly different and not yet complete.
I quickly built cryptsetup 2.x from sources on Armbian, was not as tough as I expected - pretty straightforward: configure, correct & configure, correct & ...
cryptsetup 2.x requires the following packages to be installed:
- uuid-dev
- libdevmapper-dev
- libpopt-dev
- pkg-config
- libgcrypt-dev
- libblkid-dev
Not sure about these ones, but I installed them anyway:
- libdmraid-dev
- libjson-c-dev
Build & install:
- Download cryptsetup 2.x via https://gitlab.com/cryptsetup/cryptsetup/tree/master.
- Unxz the tarball.
- ./configure --prefix=/usr/local
- make
- sudo make install
- sudo ldconfig
Configuration:
- 2x WD Blue 2TB HDDs.
- 4KiB sector aligned GPT partitions.
- mdadm RAID6 (degraded).
Test:
-
Write
10GiB4GiB worth of zeroes; dd if=/dev/zero of=[dut] bs=4096 count=1048576 conv=fsync.- directly to mdadm device.
- to a file on an XFS filesystem on top of an mdadm device.
- directly to LUKS2 device on top of an mdadm device (512B/4096KiB sector sizes for LUKS2).
- to a file on an XFS filesystem on top of a LUKS2 device on top of an mdadm device (512B/4096KiB sector sizes for LUKS2).
Results:
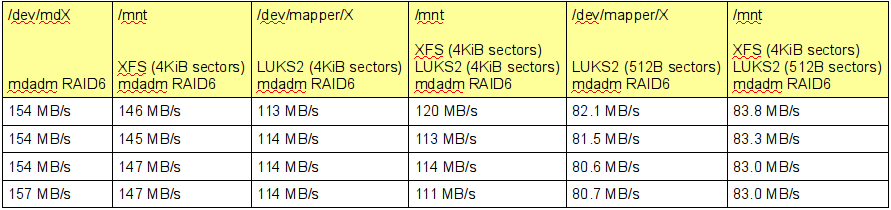
Caveat:- CPU load is high: >75% due to mdadm using CPU for parity calculations. If using the box as just a fileserver for a handful of clients, this should be no problem. But if more processing is done besides serving up files, e.g. transcoding, (desktop) applications, this might become problematic.
- RAID6 under test was in degraded mode. I don't have enough disks to have a fully functional RAID6 array yet. No time to tear down my old server yet. Having a full RAID6 array might impact parity calculations and add 2x more disk I/O to the mix.
I might consider re-encrypting the disks on my first box, to see if LUKS2 w/4KiB sectors will increase the SnapRAID performance over the LUKS(1) w/512B sectors. Currently it takes over 13 hours to scrub 50% on a 2-parity SnapRAID configuration holding less than 4TB of data.
-[ update ]-
Additional test:
-
Write/read 4GiB worth of zeroes to a file on an XFS filesystem test on armbian/linux packages 5.73 (upgraded from 5.70)
-
for i in {0..9} ;
do time dd if=/dev/zero of=removeme.${i} bs=4096 count=$(( 4 * 1024 * 1024 * 1024 / 4096 )) conv=fsync;
dd if=removeme.$(( 9 - ${i} )) of=/dev/null bs=4096 ;
done 2>&1 | egrep '.*bytes.*copied.*'
-
for i in {0..9} ;
Results:
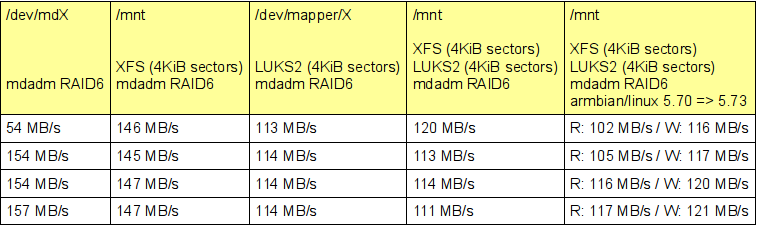
The write throughput appears to be slightly higher, as now the XOR HW engine is being used - but it could just as well be measurement noise.
CPU load is still quite high during this new test:
%Cpu0 : 0.0 us, 97.5 sy, 1.9 ni, 0.3 id, 0.3 wa, 0.0 hi, 0.0 si, 0.0 st %Cpu1 : 0.3 us, 91.4 sy, 1.1 ni, 0.0 id, 0.0 wa, 0.0 hi, 7.2 si, 0.0 st <snip> 176 root 20 0 0 0 0 R 60.9 0.0 14:59.42 md0_raid6 1807 root 30 10 1392 376 328 R 45.7 0.0 0:10.97 dd 9087 root 0 -20 0 0 0 D 28.5 0.0 1:16.53 kworker/u5:1 34 root 0 -20 0 0 0 D 19.0 0.0 0:53.93 kworker/u5:0 149 root -51 0 0 0 0 S 14.4 0.0 3:19.35 irq/38-f1090000 150 root -51 0 0 0 0 S 13.6 0.0 3:12.89 irq/39-f1090000 5567 root 20 0 0 0 0 S 9.5 0.0 1:09.40 dmcrypt_write <snip>
Will update this again once the RAID6 array set up is complete.
Groetjes,
-
Hi,
I'm not sure if this is a known bug or not, but just posting here FYI.
I've been tinkering with 'fancontrol' recently. During testing I found that 'fancontrol' leaves the fans full stop when it bails out on any error. The 'disablepwm' function seems to have a tiny bug that actually sets the PWM value to it's minimum value in case a 'pwmX_enable' file cannot be found - which is the case for Armbian on Helios4:
# ls /dev/fan-j1[07]/ /sys/class/hwmon/hwmon[23]/ /dev/fan-j10/: device name of_node power pwm1 subsystem uevent /dev/fan-j17/: device name of_node power pwm1 subsystem uevent /sys/class/hwmon/hwmon2/: device name of_node power pwm1 subsystem uevent /sys/class/hwmon/hwmon3/: device name of_node power pwm1 subsystem ueventThis minimum value causes the fans on my box to come to a full stop.
For my box, in case 'fancontrol' bails out, I'd like the fans to go full speed.
# $1 = pwm file name function pwmdisable() { local ENABLE=${1}_enable # No enable file? Just set to max if [ ! -f $ENABLE ] then ##[BUG] echo $MINPWM > $1 ##[BUG] return 0 ##[begin] Fixup to make sure fans return to their full speed when we bail out for VALUE in "${MAXPWM:-}" "${MAX:-}" '255' do if expr "${VALUE:-}" : '^[0-9][0-9]*$' > /dev/null then # VALUE looks like a numerical value if ( echo "${VALUE:-255}" > $1 ) then echo "Successfully written value '${VALUE:-N/A}' to PWM file '${1:-N/A}'." return # to caller fi # ...try next method fi done false returnThe fixup above worked for me, but USE AT YOUR OWN RISK.
Groetjes,
-
@Koen, do note that on Armbian, the CESA modules are not loaded per default, so even if you choose aes-cbc-essiv but do not load the appropriate kernel module, the CESA is not utilized. (See the cryptsetup benchmark results with- and without marvell_cesa/mv_cesa.)
For the XTS vs CBC I will try to find & list the articles I found on the interwebs.
@gprovost, thanks for the tip, I'll refrain from loading mv_cesa.
-
Ok, I've made some progress already: It turns out that LUKS performance gets a boost when using cipher 'aes-cbc-essiv:sha256'. Key size did not really show any big difference during testing simple filesystem performance (~102MiB/sec vs ~103MiB/sec). The internets say that there is some concern about using cbc vs xts, but after some reading it looks like it's not necessarily a concern related to the privacy of the data, but more of an data integrity issue. Attackers are able to corrupt encrypted content in certain scenarios. For my use case, this is not a problem at all, so I'm happy to see the performance boost by using CESA!
Test setup & playbook:
- Make sure 'marvell-cesa' and 'mv_cesa' are modprobe'd.
- /dev/sdX1 - optimally aligned using parted.
- luksFormat /dev/sdX1
- luksOpen /dev/sdX1 decrypt
- mkfs.xfs /dev/mapper/decrypt
- mount /dev/mapper/decrypt /mnt
- Check /proc/interrupts
- dd if=/dev/zero of=/mnt/removeme bs=1048576 count=16384 conv=fsync
- Check /proc/interrupts if crypto has gotten any interrupts.
Averaged throughput measurement:
-
Cipher: aes-xts-plain64:sha1, key size: 256bits
- Throughput => 78.0 MB/s,
- Interrupts for crypto => 11 + 8,
-
Cipher: aes-cbc-essiv:sha256, key size: 256bits
- Throughput => 102 MB/s,
- Interrupts for crypto => 139421 + 144352,
-
Cipher: aes-cbc-essiv:sha256, key size: 128bits
- Throughput => 103 MB/s
- Interrupts for crypto => 142679 + 152079.
Next steps;
- Copy all content from the aes-xts LUKS volumes to the aes-cbc LUKS volumes,
- Run snapraid check/diff/sync and check disk throughput.
Comments are welcome,
Groetjes,
-
Hi, I would be interested in the LUKS benchmark results as well, with and without using the CESA.
Currently I'm trying to get my LUKS encrypted volumes to perform a bit better on the Helios4. On my previous box (AMD Athlon X2) I saw numbers above 80 MiB/sec for disk I/O when performing a 'snapraid diff/sync/scrub' on the same LUKS encrypted volumes. The drives themselves were the I/O bottleneck. On the Helios4, those numbers have dropped significantly: ~30MiB/sec for the same actions.
On the Helios4, with 'marvell-cesa' and 'mv_cesa' modules loaded, 'cryptsetup benchmark' shows:
/* snip */ # Algorithm | Key | Encryption | Decryption aes-cbc 128b 101.3 MiB/s 104.2 MiB/s serpent-cbc 128b 27.8 MiB/s 29.4 MiB/s twofish-cbc 128b 39.7 MiB/s 44.2 MiB/s aes-cbc 256b 91.7 MiB/s 94.1 MiB/s serpent-cbc 256b 28.0 MiB/s 32.0 MiB/s twofish-cbc 256b 39.7 MiB/s 44.3 MiB/s aes-xts 256b 63.4 MiB/s 55.0 MiB/s serpent-xts 256b 27.6 MiB/s 31.8 MiB/s twofish-xts 256b 43.3 MiB/s 44.0 MiB/s aes-xts 512b 47.9 MiB/s 41.6 MiB/s serpent-xts 512b 29.8 MiB/s 31.8 MiB/s twofish-xts 512b 43.2 MiB/s 44.0 MiB/Without the CESA modules loaded, the aes-cbc performance drops significantly:
/* snip */ # Algorithm | Key | Encryption | Decryption aes-cbc 128b 25.1 MiB/s 56.2 MiB/s serpent-cbc 128b 28.0 MiB/s 31.9 MiB/s twofish-cbc 128b 39.7 MiB/s 44.3 MiB/s aes-cbc 256b 19.1 MiB/s 42.1 MiB/s serpent-cbc 256b 27.9 MiB/s 29.2 MiB/s twofish-cbc 256b 39.5 MiB/s 44.2 MiB/s aes-xts 256b 63.2 MiB/s 55.3 MiB/s serpent-xts 256b 29.8 MiB/s 31.8 MiB/s twofish-xts 256b 43.5 MiB/s 44.2 MiB/s aes-xts 512b 48.0 MiB/s 41.6 MiB/s serpent-xts 512b 27.3 MiB/s 31.7 MiB/s twofish-xts 512b 43.3 MiB/s 44.1 MiB/sThis already hints at the fact that 'dm-crypt' is not using the CESA.
After some checking, I would need to reencrypt my LUKS drives; they're using aes-xts-sha1, which is not supported by the CESA according to the Helios4 Wiki. The benchmark results shown by 'cryptsetup benchmark' show only an improvement for the aes-cbc algorithms, so first test will be to see what LUKS will do with 128bit aes-cbc-sha1 instead of 256bit aes-xts-sha1.
Groetjes,
p.s. I'm in no way a cryptography expert, so some of the terms might not be hitting the mark completely
Helios4 Support
in Marvell mvebu
Posted
Hi,
A quick update to all who have Helios4 boxes freeze up. After board replacement and switching PSUs, the box still froze from time to time. After the last freeze, I decided to move the rootfs to a USB stick, to rule out anything related to the SDcard.
The SDcard is a SanDisk Ultra. 32GB class 10 A1 UHS-I HC1 type of card, picture below.
After using the SDcard for booting kernel + initrd only, the box has been going strong for quite a while, when under load and when idling around:
07:39:29 up 21 days, 29 min, 6 users, load average: 0.14, 0.14, 0.10Note that the uptime is actually more than shown, but the box has been rebooted due to unrelated issues and some planned downtime.
Hope this will help any of you.
Groetjes,