Search the Community
Showing results for tags 'helios64'.
-
Just a reminder, if someone wants to fix it.
-
I have a Helios64 that I recently reinstalled/updated to the latest Armbain Jammy image after not updating for quite some time and finding some of the repos to be dead. Without the drives initialized the system seems like it will run for days, but with the drives initialized (ZFS), I will get the below error after a few hours of uptime (~8-10 hours). I have seen some threads saying to set the CPU clock to one speed to fix the issue and some people installing a newer kernel (via beta.armbian.com). If anyone has any thoughts on how I could try and make this more stable I would appreciate it. [477435.475903] rcu: INFO: rcu_preempt self-detected stall on CPU [477435.476481] rcu: 3-....: (90606038 ticks this GP) idle=8c74/1/0x4000000000000000 softirq=715905/93001225 fqs=43038032 [477435.477488] rcu: (t=90606039 jiffies g=2287601 q=1361150 ncpus=6) [477549.183778] rcu: INFO: rcu_preempt detected expedited stalls on CPUs/tasks: { 1-.... 3-.... } 65978929 jiffies s: 781 root: 0xa/. [477549.184885] rcu: blocking rcu_node structures (internal RCU debug): [477615.481330] rcu: INFO: rcu_preempt self-detected stall on CPU [477615.481904] rcu: 3-....: (90651041 ticks this GP) idle=8c74/1/0x4000000000000000 softirq=715905/93047138 fqs=43059171 [477615.482913] rcu: (t=90651042 jiffies g=2287601 q=1361150 ncpus=6) [477729.401197] rcu: INFO: rcu_preempt detected expedited stalls on CPUs/tasks: { 1-.... 3-.... } 66023985 jiffies s: 781 root: 0xa/. [477729.402304] rcu: blocking rcu_node structures (internal RCU debug): [477795.486758] rcu: INFO: rcu_preempt self-detected stall on CPU [477795.487338] rcu: 3-....: (90696044 ticks this GP) idle=8c74/1/0x4000000000000000 softirq=715905/93092997 fqs=43080230 [477795.488344] rcu: (t=90696045 jiffies g=2287601 q=1361150 ncpus=6) [477909.618629] rcu: INFO: rcu_preempt detected expedited stalls on CPUs/tasks: { 1-.... 3-.... } 66069041 jiffies s: 781 root: 0xa/. [477909.619735] rcu: blocking rcu_node structures (internal RCU debug): [477975.492185] rcu: INFO: rcu_preempt self-detected stall on CPU [477975.492764] rcu: 3-....: (90741047 ticks this GP) idle=8c74/1/0x4000000000000000 softirq=715905/93138939 fqs=43101769 [477975.493771] rcu: (t=90741048 jiffies g=2287601 q=1361150 ncpus=6) [478089.836039] rcu: INFO: rcu_preempt detected expedited stalls on CPUs/tasks: { 1-.... 3-.... } 66114097 jiffies s: 781 root: 0xa/. [478089.837147] rcu: blocking rcu_node structures (internal RCU debug):
-
 I tried to install OMV 7 RC1 on the Bookworm image, but I get a lot of "Segmentation fault" and "free(): invalid pointer" error messages. My Installation for the Bookworm image... Is the problem due to the Bookworm image or the 6.6.8 kernel or should I contact the OMV team? Here is the complete log of the OMV 7 RC1 installation...
I tried to install OMV 7 RC1 on the Bookworm image, but I get a lot of "Segmentation fault" and "free(): invalid pointer" error messages. My Installation for the Bookworm image... Is the problem due to the Bookworm image or the 6.6.8 kernel or should I contact the OMV team? Here is the complete log of the OMV 7 RC1 installation... -
If so how'd ya do it!?!? My personal experience had been a rock solid device on the original official Debian Armbian image (Linux Kernel: 5.10), and OMV5. It never went down unless I manually rebooted, and I never needed any CPU governor changes, voltage changes or otherwise to keep it stable. Reading so much stuff about OMV5 being end of life made me pull the trigger on upgrade to OMV6 along with the kernel upgrade that OMV did automatically, at the time unaware of the state of Kobol and Armbian support. Now I get about 1-2 days on average before it KPs and I have to hit the reset button. Tried the CPU underclocking, performance setting, VDD boost and various combinations but to no avail. So just reaching out to any other users here, is anyone still rocking a stable unit in 2023? Did you have to revert to Buster / OMV5? Are there any other tweaks to try that I've missed other than CPU clock/profile/vdd tweak? Is there any way to get any information on why it might be happening? Or is the only way to have a hardware serial console open 24/7 via a usb cable?
-
Hello! I'm able to reproducibly get a kernel oops whenever I start a docker container on my Helios64 The SD card I was running my Helios64 from died and so I reinstalled Armbian using the steps to install bookworm from this post. I did skip the steps related to hs400 and L2 cache as I'm currently running the system from an SD card. After the install seemed to be working well I installed zfs, imported my existing pool, and then installed docker. My previous setup was using docker's ZFS storage driver so I got that configured as well. Now, whenever I start up a docker container (ie by running "sudo docker run hello-world") I get the following oops from the kernel: [ 246.422387] Unable to handle kernel NULL pointer dereference at virtual address 0000000000000038 [ 246.422400] Mem abort info: [ 246.422403] ESR = 0x0000000096000005 [ 246.422406] EC = 0x25: DABT (current EL), IL = 32 bits [ 246.422411] SET = 0, FnV = 0 [ 246.422414] EA = 0, S1PTW = 0 [ 246.422417] FSC = 0x05: level 1 translation fault [ 246.422421] Data abort info: [ 246.422423] ISV = 0, ISS = 0x00000005, ISS2 = 0x00000000 [ 246.422426] CM = 0, WnR = 0, TnD = 0, TagAccess = 0 [ 246.422430] GCS = 0, Overlay = 0, DirtyBit = 0, Xs = 0 [ 246.422434] user pgtable: 4k pages, 48-bit VAs, pgdp=000000000942d000 [ 246.422439] [0000000000000038] pgd=0800000016225003, p4d=0800000016225003, pud=0000000000000000 [ 246.422452] Internal error: Oops: 0000000096000005 [#1] PREEMPT SMP [ 246.423015] Modules linked in: veth xt_nat xt_tcpudp xt_conntrack nft_chain_nat xt_MASQUERADE nf_nat nf_conntrack_netlink nf_conntrack nf_defrag_ipv6 nf_defrag_ipv4 xfrm_user xfrm_algo xt_addrtype nft_compat nf_tables nfnetlink br_netfilter bridge rfkill sunrpc lz4hc lz4 zram binfmt_misc zfs(PO) crct10dif_ce leds_pwm panfrost spl(O) gpio_charger gpu_sched drm_shmem_helper pwm_fan snd_soc_hdmi_codec snd_soc_rockchip_i2s rockchip_vdec(C) hantro_vpu rk_crypto snd_soc_core rockchip_rga snd_compress v4l2_vp9 v4l2_h264 videobuf2_dma_sg videobuf2_dma_contig ac97_bus v4l2_mem2mem snd_pcm_dmaengine snd_pcm videobuf2_memops videobuf2_v4l2 snd_timer videodev nvmem_rockchip_efuse videobuf2_common mc snd soundcore gpio_beeper ledtrig_netdev lm75 ip_tables x_tables autofs4 efivarfs raid10 raid456 async_raid6_recov async_memcpy async_pq async_xor async_tx raid1 raid0 multipath linear cdc_ncm cdc_ether usbnet r8152 realtek rockchipdrm dw_mipi_dsi fusb302 dw_hdmi tcpm analogix_dp dwmac_rk typec drm_display_helper stmmac_platform cec [ 246.423214] drm_dma_helper stmmac drm_kms_helper drm adc_keys pcs_xpcs [ 246.431612] CPU: 5 PID: 2686 Comm: dockerd Tainted: P C O 6.6.8-edge-rockchip64 #1 [ 246.432383] Hardware name: Helios64 (DT) [ 246.432731] pstate: 60000005 (nZCv daif -PAN -UAO -TCO -DIT -SSBS BTYPE=--) [ 246.433344] pc : get_device_state+0x28/0x88 [ledtrig_netdev] [ 246.433854] lr : netdev_trig_notify+0x13c/0x1fc [ledtrig_netdev] [ 246.434387] sp : ffff80008b2ab3e0 [ 246.434680] x29: ffff80008b2ab3e0 x28: ffff0000154d3378 x27: ffff80007a36dc30 [ 246.435313] x26: ffff800081c89a40 x25: ffff800081907008 x24: ffff80008b2ab5b8 [ 246.435944] x23: 000000000000000b x22: ffff000005efb000 x21: ffff0000154d3300 [ 246.436575] x20: ffff0000154d3378 x19: ffff0000154d3300 x18: ffff80008d293c58 [ 246.437206] x17: 000000040044ffff x16: 00500074b5503510 x15: 0000000000000000 [ 246.437837] x14: ffffffffffffffff x13: 0000000000000020 x12: 0101010101010101 [ 246.438468] x11: 7f7f7f7f7f7f7f7f x10: 000000000f5d83a0 x9 : 0000000000000020 [ 246.439099] x8 : 0101010101010101 x7 : 0000000080000000 x6 : 0000000080303663 [ 246.439729] x5 : 6336300000000000 x4 : 0000000000000000 x3 : 0000000000000000 [ 246.440360] x2 : ffff000021bdbc00 x1 : ffff000021bdbc00 x0 : 0000000000000000 [ 246.440991] Call trace: [ 246.441210] get_device_state+0x28/0x88 [ledtrig_netdev] [ 246.441683] netdev_trig_notify+0x13c/0x1fc [ledtrig_netdev] [ 246.442185] notifier_call_chain+0x74/0x144 [ 246.442561] raw_notifier_call_chain+0x18/0x24 [ 246.442956] call_netdevice_notifiers_info+0x58/0xa4 [ 246.443399] dev_change_name+0x190/0x318 [ 246.443751] do_setlink+0xb7c/0xde4 [ 246.444064] rtnl_setlink+0xf8/0x194 [ 246.444383] rtnetlink_rcv_msg+0x12c/0x398 [ 246.444748] netlink_rcv_skb+0x5c/0x128 [ 246.445089] rtnetlink_rcv+0x18/0x24 [ 246.445408] netlink_unicast+0x2e8/0x350 [ 246.445755] netlink_sendmsg+0x1d4/0x444 [ 246.446102] __sock_sendmsg+0x5c/0xac [ 246.446432] __sys_sendto+0x124/0x150 [ 246.446760] __arm64_sys_sendto+0x28/0x38 [ 246.447117] invoke_syscall+0x48/0x114 [ 246.447453] el0_svc_common.constprop.0+0x40/0xe8 [ 246.447871] do_el0_svc+0x20/0x2c [ 246.448168] el0_svc+0x40/0xf4 [ 246.448442] el0t_64_sync_handler+0x13c/0x158 [ 246.448829] el0t_64_sync+0x190/0x194 [ 246.449158] Code: f9423c20 f90047e0 d2800000 f9404e60 (f9401c01) [ 246.449695] ---[ end trace 0000000000000000 ]--- TIA for the help and for keeping this unsupported hardware alive!
-
 Hi, I use Helios64 from the begin and this board is very unstable according to my experience and many posts here... After many dialogue here and settings shared about Frequency and Governor Kernel... maybe i find the problem and i ask anyone return of experiences about the procedure and setting belong: - Connect USB Wireless Dongle or USB(-c) Ethernet Plug - Configure it - Disconnect all ethernet cable to the board - Use with last time crash configuration and do a endurance test your helios64 board Have a good day
Hi, I use Helios64 from the begin and this board is very unstable according to my experience and many posts here... After many dialogue here and settings shared about Frequency and Governor Kernel... maybe i find the problem and i ask anyone return of experiences about the procedure and setting belong: - Connect USB Wireless Dongle or USB(-c) Ethernet Plug - Configure it - Disconnect all ethernet cable to the board - Use with last time crash configuration and do a endurance test your helios64 board Have a good day -
Upgrading Helios64 from Armbian Buster to Bullseye (see below) works as expected on my system. However, I am using systemd-networkd and just a few services (nextcloud, netatalk, etc. and not ZFS) EDIT: Upgrading Buster installations to Bullseye also works fine if you use network-manager, even if you have a bridge configured (using bridge-slave; binutils-bridge). # cat /etc/os-release PRETTY_NAME="Debian GNU/Linux 11 (bullseye)" NAME="Debian GNU/Linux" VERSION_ID="11" VERSION="11 (bullseye)" VERSION_CODENAME=bullseye ID=debian HOME_URL="https://www.debian.org/" SUPPORT_URL="https://www.debian.org/support" BUG_REPORT_URL="https://bugs.debian.org/" _ _ _ _ __ _ _ | | | | ___| (_) ___ ___ / /_ | || | | |_| |/ _ \ | |/ _ \/ __| '_ \| || |_ | _ | __/ | | (_) \__ \ (_) |__ _| |_| |_|\___|_|_|\___/|___/\___/ |_| Welcome to Armbian 21.08.1 Bullseye with Linux 5.10.43-rockchip64 System load: 2% Up time: 12:29 Memory usage: 19% of 3.77G IP: xx.xx.xx.xx CPU temp: 42°C Usage of /: 41% of 15G storage/: 57% of 3.6T Edit: Attention - if you upgrade your Buster or Bullseye installation on emmc to Armbian 21.08.1 it will not be writable anymore. You will then have to downgrade linux on emmc from 5.10.60 to 5.10.43 as described in this thread. Edit: There is a temporary fix for the problem. See this message from @piter75 To upgrade Armbian Buster to Bullseye, first disable Armbian updates in /etc/apt/sources.list.d/Armbian.list for the time being. Then fully upgrade Buster (sudo apt update && sudo apt upgrade -y) , then change the apt sources (see below) followed by 'sudo apt update && sudo apt full-upgrade'. I kept all the configuration files by confirming 'N' in the following dialogue. # cat /etc/apt/sources.list deb http://deb.debian.org/debian/ bullseye main deb-src http://deb.debian.org/debian/ bullseye-updates main deb http://security.debian.org/debian-security bullseye-security main deb-src http://security.debian.org/debian-security bullseye-security main deb http://ftp.debian.org/debian bullseye-backports main
-
Dear to all, I have a Helios64 unit with 2 hdd (both WD60EFRX). I have bought also an external enclousure UGREEN 5 Bay Hard Drive Enclosure ( https://eu.ugreen.com/collections/hard-drive-enclosures/products/ugreen-5-bay-hard-drive-enclosure-5-x-18tb-raid-array-hard-disk-docking-station ) and 2 WD140EDGZ and these 2 hdd are mounted inside UGREEN enclousure because I want format and test it (when all will work fine I'll exchange a WD60EFRX with a WD140EDGZ so the drives inside the enclousure will have a backup scope). The enclousure is powered by external adapter, the system image installed is the Armbian 22.02.1 with Linux kernel 5.15.93-rockchip 64 and openmediavault 6.6.0-2 (Shaitan). If I have the enclousure turned off and from open media vault access to smart drive section (storage -> S.M.A.R.T. -> device section), the smart information (related to the 2 WD60EFRX) are showed in about 4-5 seconds but if I turn on the enclousure with the 2 device WD140EDGZ , the smart drive section is showed after 4 minutes. Sometimes the section isn't showed but it's showed an error message "Http failure response for http://192.168.1.44/rpc.php: 504 Gateway Time-out". I'm sure that this problem occur also with the transfer of files (hoping that doesn't occur wrong data information transfer with damaged files also) and I have already googled for this issue on the web but I haven't found nothing that help me to solve the issue. I attach here the 2 dmesg output that I have take from 2 distinct session with putty dmesg of first session dmesg of second session my question is: the problem it's related from standard drivers inside the image, from the kernel or it's necessary take manufacturer driver source and compile it? How can I solve this issue? Hope that somebody help me Best regards
-
Hi, Today i make upgrade to 23.11 armbian on my Helios64. It's in bookworm version (apt source list is good, no change since 23.08) but now it display this: Welcome to Armbian 23.11.1 Buster with Linux 6.1.63-current-rockchip64 No end-user support: community creations & unsupported (buster) userspace! it's a bug? thank have a nice day
-
Hello everyone, I would like to know which version of Armbian is recommended to install today to have a stable system ? Indeed, I have reset all my data on my Helios64 and I want perform a fresh install. I do not made any hardware change on my Helios64 and I plan to use OMV6. Thanks all for advices Flolm
-
Hello everyone, I would like to know which version of Armbian is recommended to install today to have a stable system ? Indeed, I have reset all my data on my Helios64 and I want perform a fresh install. I do not made any hardware change on my Helios64 and I plan to use OMV6. Thanks all for advices Flolm
-
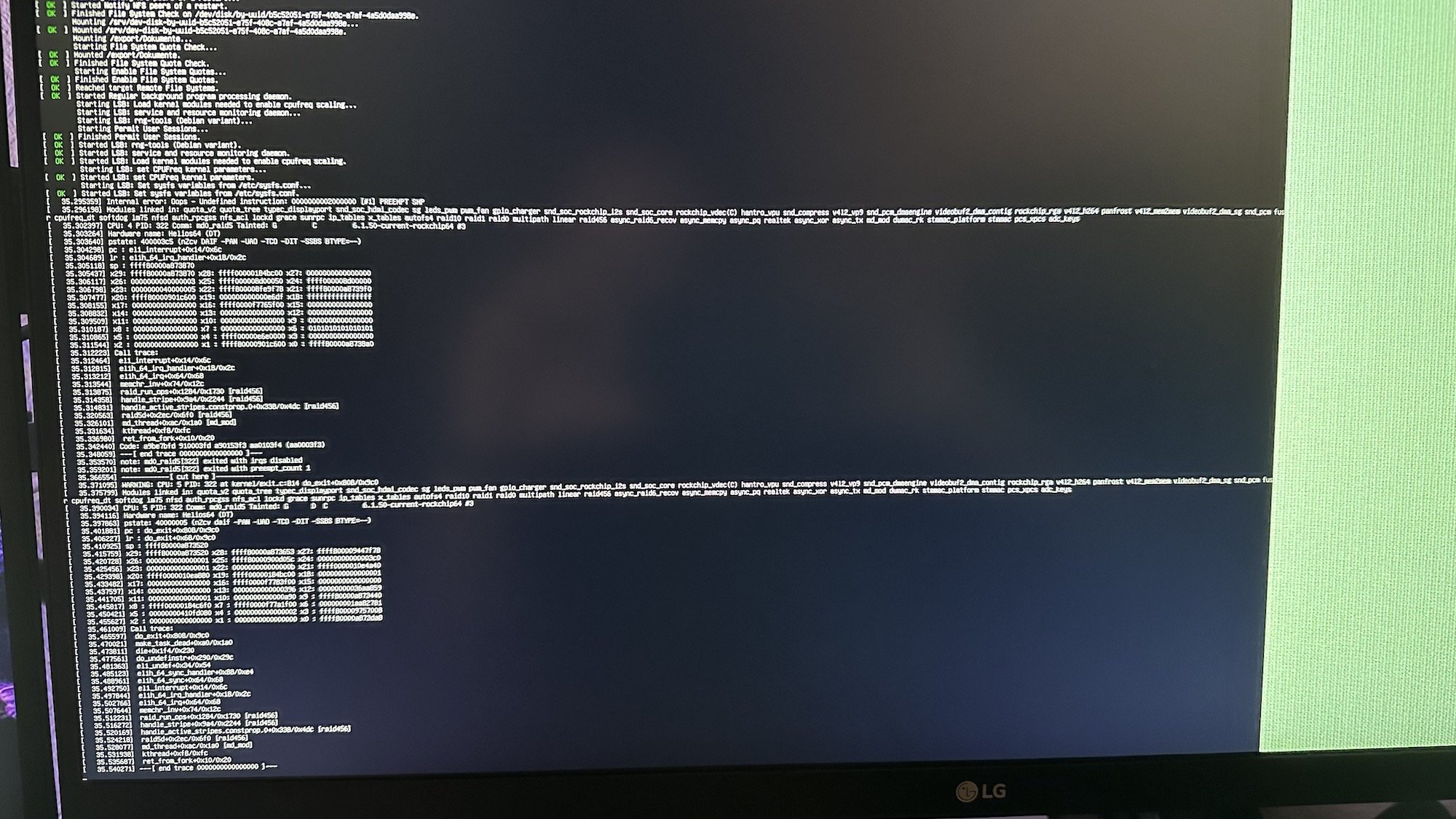
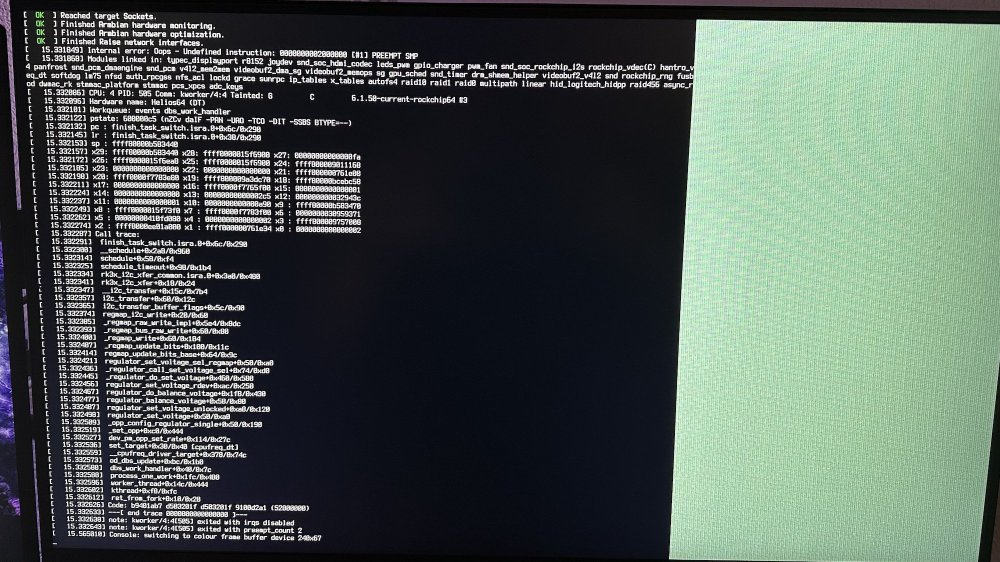
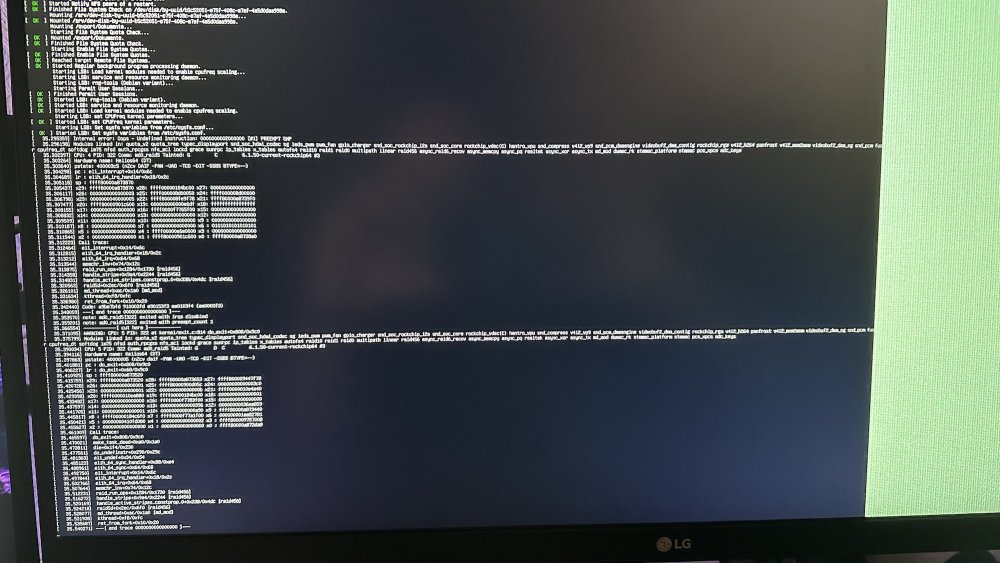
[ 184.130515] Internal error: Oops - Undefined instruction: 0000000002000000 [#1] PREEMPT SMP [ 184.131281] Modules linked in: rfkill lz4hc lz4 snd_soc_hdmi_codec snd_soc_rockchip_i2s rockchip_vdec(C) hantro_vpu v4l2_vp9 leds_pwm gpio_charger videobuf2_dma_contig pwm_fan rockchip_rga panfrost videobuf2_dma_sg v4l2_h264 gpu_sched v4l2_mem2mem snd_soc_core drm_shmem_helper snd_compress rockchip_rng rng_core snd_pcm_dmaengine videobuf2_memops snd_pcm videobuf2_v4l2 videobuf2_common snd_timer videodev snd soundcore mc zram binfmt_misc gpio_beeper cpufreq_dt ledtrig_netdev lm75 dm_mod ip_tables x_tables autofs4 raid10 raid456 async_raid6_recov async_memcpy async_pq async_xor async_tx raid1 raid0 multipath linear md_mod r8152 cdc_ncm cdc_ether usbnet realtek fusb302 tcpm typec dwmac_rk stmmac_platform stmmac pcs_xpcs adc_keys [ 184.137145] CPU: 4 PID: 0 Comm: swapper/4 Tainted: G C 6.1.36-rockchip64 #3 [ 184.137890] Hardware name: Helios64 (DT) [ 184.138243] pstate: 000003c5 (nzcv DAIF -PAN -UAO -TCO -DIT -SSBS BTYPE=--) [ 184.138866] pc : debug_smp_processor_id+0x28/0x2c [ 184.139305] lr : ct_nmi_enter+0x68/0x1a4 [ 184.139663] sp : ffff800009cabb90 [ 184.139963] x29: ffff800009cabb90 x28: ffff000000761e00 x27: 0000000000000000 [ 184.140608] x26: ffff80000901a180 x25: ffff8000093d9e80 x24: 0000000000000001 [ 184.141251] x23: ffff8000099cdc70 x22: ffff0000f777e8f0 x21: ffff8000094797a8 [ 184.141893] x20: 0000000096000007 x19: ffff8000096f68f0 x18: ffff800010813c58 [ 184.142534] x17: ffff8000ee088000 x16: ffff800009ca8000 x15: 0000000000000001 [ 184.143176] x14: 0000000000000000 x13: 00000000000002da x12: 000000000041a201 [ 184.143818] x11: 0000000000000040 x10: ffff000000404470 x9 : ffff000000404468 [ 184.144459] x8 : ffff0000008004b8 x7 : 0000000000000000 x6 : 000000001b4110bc [ 184.145100] x5 : ffff800009cabc60 x4 : 0000000000010002 x3 : ffff8000096e7008 [ 184.145741] x2 : ffff000000761e00 x1 : ffff800009415a68 x0 : 0000000000000004 [ 184.146382] Call trace: [ 184.146606] debug_smp_processor_id+0x28/0x2c [ 184.147004] ct_irq_enter+0x10/0x1c [ 184.147326] enter_from_kernel_mode+0x28/0x74 [ 184.147720] el1_abort+0x24/0x64 [ 184.148016] el1h_64_sync_handler+0xd8/0xe4 [ 184.148397] el1h_64_sync+0x64/0x68 [ 184.148715] update_curr+0x84/0x1fc [ 184.149040] enqueue_entity+0x16c/0x32c [ 184.149387] enqueue_task_fair+0x84/0x3e0 [ 184.149749] ttwu_do_activate+0x78/0x164 [ 184.150106] sched_ttwu_pending+0xec/0x1e0 [ 184.150480] __flush_smp_call_function_queue+0xec/0x254 [ 184.150949] generic_smp_call_function_single_interrupt+0x14/0x20 [ 184.151494] ipi_handler+0x90/0x350 [ 184.151816] handle_percpu_devid_irq+0xa4/0x230 [ 184.152227] generic_handle_domain_irq+0x2c/0x44 [ 184.152648] gic_handle_irq+0x50/0x130 [ 184.152991] call_on_irq_stack+0x24/0x4c [ 184.153349] do_interrupt_handler+0xd4/0xe0 [ 184.153730] el1_interrupt+0x34/0x6c [ 184.154058] el1h_64_irq_handler+0x18/0x2c [ 184.154430] el1h_64_irq+0x64/0x68 [ 184.154738] arch_cpu_idle+0x18/0x2c [ 184.155065] default_idle_call+0x38/0x17c [ 184.155428] do_idle+0x23c/0x2b0 [ 184.155727] cpu_startup_entry+0x24/0x30 [ 184.156085] secondary_start_kernel+0x124/0x150 [ 184.156496] __secondary_switched+0xb0/0xb4 [ 184.156882] Code: 9107c000 97ffffb0 a8c17bfd d50323bf (d65f03c0) [ 184.157427] ---[ end trace 0000000000000000 ]--- [ 184.157841] Kernel panic - not syncing: Oops - Undefined instruction: Fatal exception in interrupt [ 184.158632] SMP: stopping secondary CPUs [ 184.158993] Kernel Offset: disabled [ 184.159307] CPU features: 0x20000,20834084,0000421b [ 184.159745] Memory Limit: none [ 184.160030] ---[ end Kernel panic - not syncing: Oops - Undefined instruction: Fatal exception in interrupt ]--- This is getting more and more frequent -- the CPU changes but mostly it is 4 or 5 I have no idea as to where to start/what to do next - So I came here... a friend at work says the boards should be cheap enough - buy a new one --- I don't seem to be able to find a source for this particular board... I think it is a custom "tinkerboard" overall this is/was the Helios64 NAS which Worked rocksolid -- until it didn't I can't remember if I updated the OS and then it started failing -- or what -- at the moment - it is running whatever was the latest 2 weeks ago... above is the dump it leaves when it crashes - I have the board out of the cast and on my test desk -- when it does boot -- ( if / when ) --- I shell into it -- if it stays up - I run BTOP after whatever length of time -- I try to shell in for a second session - and try to run armbian-config don't often get this far... help? if asked I can provide the boot sequence text... Rich Leonard
-
After happily using my helios64 with armbian buster for years I finally dared to upgrade and everything went smoothly. I found instructions somewhere here in this forum and this is what I did. I first commented out /etc/apt/sources.list.d/armbian.list Then I upgraded to bullseye by replacing everything buster with bullseye in /etc/apt/sources.list (I think I also had to change the url to the security repo) Then I did apt-get update && apt full-upgrade and rebooted. Great success! Then the same for bookworm and again great success. Then reenabled the armbian apt repo with bookworm. again full-upgrade, reboot and again great success. Now I have kernel 6.1.50-current-rockchip64 Now the thing I don't understand: When I ssh to the machine it still lists buster and /etc/armbian-release is untouched. I checked a bit and /etc/armbian-release is part of linux-buster-root-current-helios64 on my system which sounds suspicious. The package seems to contain super integral parts of the system. udev rules, systemd rules etcpp. and is still installed. I don't see an obvious replacement for it. Can somebody shed some light on it? What did I miss?
-
I updated my Helios64 last night and now it keeps rebooting. Every now and then it runs for a few minutes so I can log in via ssh and then it reboots all at once. Installed on the system is only OMV 6.9.1-1 (Shaitan) and Docker with the image of Emby. the system runs on an installed M.2 SSD on slot 1. 4TB WD Reds are installed in slots 2, 3 and 5. Welcome to Armbian 23.8.1 Bullseye with Linux 6.1.50-current-rockchip64 No end-user support: community creations System load: 9% Up time: 4 min Memory usage: 17% of 3.77G IP: 172.18.0.1 172.17.0.1 192.168.180.5 CPU temp: 42°C Usage of /: 7% of 117G helios@helios64:~# uname -a Linux helios64 6.1.50-current-rockchip64 #3 SMP PREEMPT Wed Aug 30 14:11:13 UTC 2023 aarch64 GNU/Linux helios@helios64:~# helios@helios64:~# cat /etc/os-release PRETTY_NAME="Armbian 23.8.1 bullseye" NAME="Debian GNU/Linux" VERSION_ID="11" VERSION="11 (bullseye)" VERSION_CODENAME=bullseye ID=debian HOME_URL="https://www.armbian.com" SUPPORT_URL="https://forum.armbian.com" BUG_REPORT_URL="https://www.armbian.com/bugs" ARMBIAN_PRETTY_NAME="Armbian 23.8.1 bullseye" the limits set for the CPU... helios@helios64:~# cat /sys/devices/system/cpu/cpufreq/policy*/scaling_max_freq 1416000 1800000 helios@helios64:~# cat /sys/devices/system/cpu/cpufreq/policy*/scaling_min_freq 408000 408000 helios@helios64:~# cat /sys/devices/system/cpu/cpufreq/policy*/scaling_cur_freq 1008000 408000 does anyone have an idea where I can start looking for the error?
-
Hi, I've got a Helios64 device running with OpenMediaVault 6.9.2-1 (Shaitan). kobol@helios64:~$ uname -a Linux helios64 6.1.50-current-rockchip64 #3 SMP PREEMPT Wed Aug 30 14:11:13 UTC 2023 aarch64 GNU/Linux It has been stable until I recently install openmediavault-photoprism 6.0.9-1 plugin provided by OMV6 through a podman container. I want to use PhotoPrism to help categorize my photos. The issue is my device systematically reboots during photo folder initial scan: the scan actually loads the system a lot, and in this state of activities, a reboot occurs after about 30 minutes to 4 hours. I first thought of a CPU temperature issue, it seems stabilized at about 64°C. But then, I caught the last journal entry before SSH disconnection: Oct 06 14:17:37 helios64 kernel: rcu: INFO: rcu_preempt detected stalls on CPUs/tasks: Oct 06 14:17:37 helios64 kernel: rcu: 4-...0: (0 ticks this GP) idle=5b4c/1/0x4000000000000000 softirq=564112/564112 fqs=3016 Oct 06 14:17:37 helios64 kernel: (detected by 1, t=15005 jiffies, g=827657, q=216 ncpus=6) Oct 06 14:17:37 helios64 kernel: Task dump for CPU 4: Oct 06 14:17:37 helios64 kernel: task:photoprism state:R running task stack:0 pid:4761 ppid:4235 flags:0x00000802 Oct 06 14:17:37 helios64 kernel: Call trace: Oct 06 14:17:37 helios64 kernel: __switch_to+0xf0/0x170 Oct 06 14:17:37 helios64 kernel: 0xffff80001186bca8 Oct 06 14:17:37 helios64 kernel: rcu: INFO: rcu_preempt detected stalls on CPUs/tasks: Oct 06 14:17:37 helios64 kernel: rcu: 4-...0: (0 ticks this GP) idle=5b4c/1/0x4000000000000000 softirq=564112/564112 fqs=12017 Oct 06 14:17:37 helios64 kernel: (detected by 3, t=60010 jiffies, g=827657, q=445 ncpus=6) Oct 06 14:17:37 helios64 kernel: Task dump for CPU 4: Oct 06 14:17:37 helios64 kernel: task:photoprism state:R running task stack:0 pid:4761 ppid:4235 flags:0x00000802 Oct 06 14:17:37 helios64 kernel: Call trace: Oct 06 14:17:37 helios64 kernel: __switch_to+0xf0/0x170 Oct 06 14:17:37 helios64 kernel: 0xffff80001186bca8 Oct 06 14:17:37 helios64 kernel: rcu: INFO: rcu_preempt detected stalls on CPUs/tasks: Oct 06 14:17:37 helios64 kernel: rcu: 4-...0: (0 ticks this GP) idle=5b4c/1/0x4000000000000000 softirq=564112/564112 fqs=21018 Oct 06 14:17:37 helios64 kernel: (detected by 3, t=105015 jiffies, g=827657, q=681 ncpus=6) Oct 06 14:17:37 helios64 kernel: Task dump for CPU 4: Oct 06 14:17:37 helios64 kernel: task:photoprism state:R running task stack:0 pid:4761 ppid:4235 flags:0x00000802 Oct 06 14:17:37 helios64 kernel: Call trace: Oct 06 14:17:37 helios64 kernel: __switch_to+0xf0/0x170 Oct 06 14:17:37 helios64 kernel: 0xffff80001186bca8 So, I draw a link (possibly wrong) between PhotoPrism preempting the computing power, and the device shuting down. The system then starts again on watchdog signal and boots without issue. My last test was to have the system running with PhotoPrism plugin active, however without scanning activities. At this low workload, the system didn't reboot for the 4 days I let it. Have you got any clue on how I can confirm such preempt signal may cause a system shutdown?
-
Hello, after some u-boot test, my helios64 don't start the bootloader stage. I can etablish a serial connection on USB Type-c port, but when I tried to start the system, I have no output on it. After I disconnected everything : - I connect usb-c cable, I'm able to connect to serial console with picocom - I connect the power cable, The LED1 (System Rail Power) is on, and the LED9 (Battery Status) flashes. - I press the power botton (without sdcard) : - LED2 and LED3 (Periph. Rail Power and HDD Rail Power) are on - LED4 and LED5 (System ON and HDD Activity) are on. - nothing happen on serial console - If I keep SWI (power botton pressed 5 seconds, i'm able to shutdown the system. I also follow the process of Maskrom Mode (https://wiki.kobol.io/helios64/maskrom/) with success, with no difference at end. > $ sudo tools/rkdeveloptool db rk3399_loader_v1.24_RevNocRL.126.bin > Downloading bootloader succeeded. > $ sudo tools/rkdeveloptool wl 0 /mnt/astav/distrib/Helios64/Armbian_21.05.1_Helios64_buster_current_5.10.35.img > Write LBA from file (100%) > $ sudo tools/rkdeveloptool rd > Reset Device OK. Questions : - What is the role of SPI Flash in the boot process ? - Does the SPI Flash can be erased ? And if yes, this can be affect the boot process ? - Can we supposed to be able to boot the armbian image writen on sd-card with SPI FLash skipped from the boot ? (with P11 jumper closed) - Could the Maskmode procedure help me, or allow me to repair my card ? - u-boot TPL is supposed to be writed on armbian sdcard ? - armbian image (like Armbian_21.05.1_Helios64_buster_current_5.10.35.img) are supposed to be able to boot, even when SPI and eMMc boot are skipped ? Thank you in advance for any help you can give me
-
I have the Helios64 NAS and am now at the point where I'll either get it working or toss it out and get something else.... it boots and runs and stops most of the time let's get some of the basics out of the way so we can figure out if here is the "best" spot to get help... uname -a returns root@helios64:/home/rmleonard# uname -a Linux helios64 5.10.21-rockchip64 #21.02.3 SMP PREEMPT Mon Mar 8 01:05:08 UTC 2021 aarch64 GNU/Linux cat /etc/os-release root@helios64:/home/rmleonard# cat /etc/os-release PRETTY_NAME="Debian GNU/Linux 10 (buster)" NAME="Debian GNU/Linux" VERSION_ID="10" VERSION="10 (buster)" VERSION_CODENAME=buster ID=debian HOME_URL="https://www.debian.org/" SUPPORT_URL="https://www.debian.org/support" BUG_REPORT_URL="https://bugs.debian.org/" ( I have tried the most current versions of the downloads and it still does about the same) I hope that is enough to help start a conversation.. Rich Leonard
-
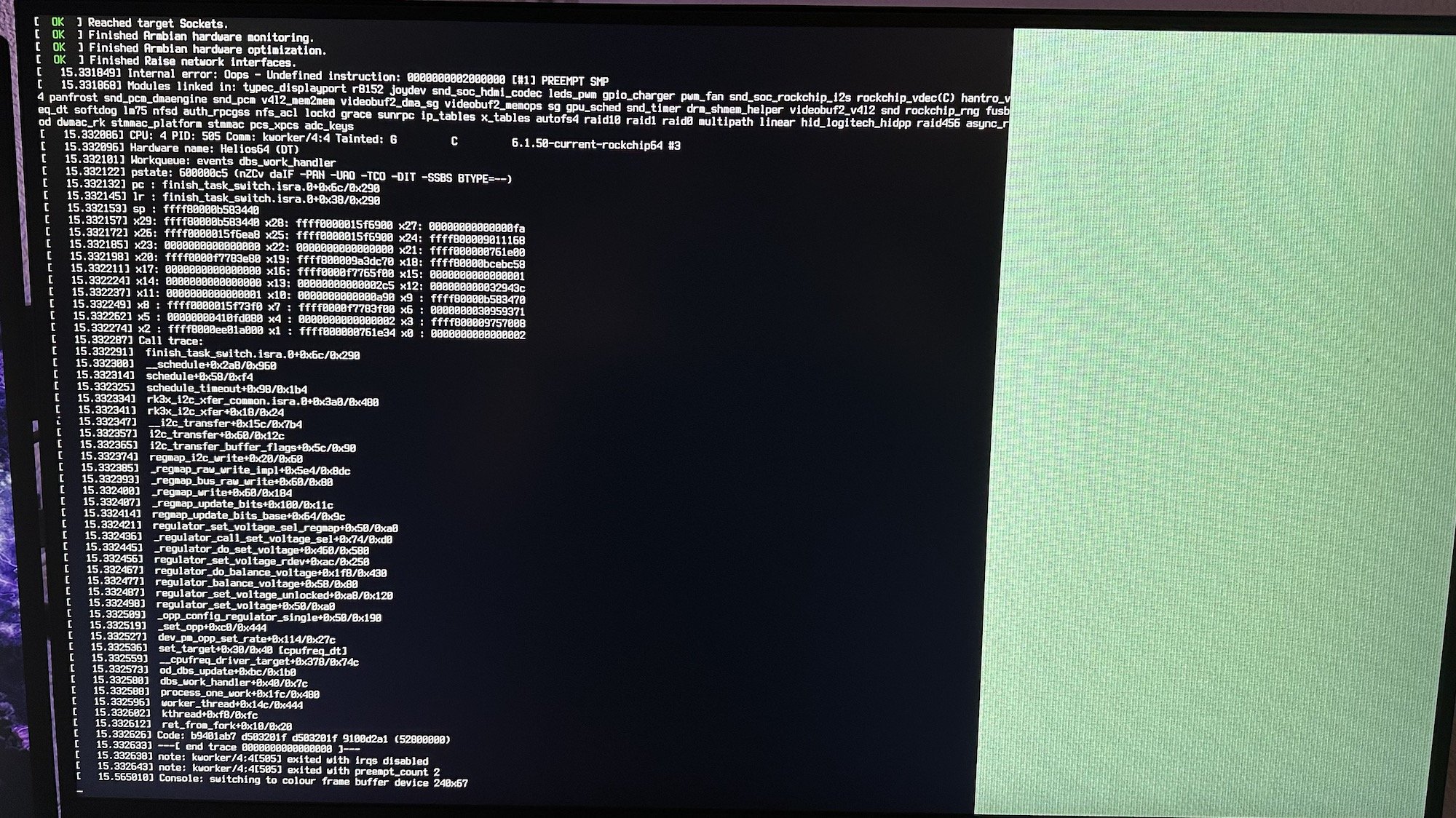
Hello, with the last kernel update I have untimely reboot of my nas. some info : hardware : helios64 os : armbian bullseye based with openmediavault 6 on top kernel : armbian-bsp-cli-helios64-current:arm64 23.8.1 before the update to armbian-bsp-cli 23.8.1 the system have some unexpected restarts, but less than 1 by day. With last version, the system restarts itself sometime only few minutes after the start. With a debug console, I got the following kernel panic : [ 510.791607] Internal error: Oops: 0000000096000044 [#1] PREEMPT SMP [ 510.792174] Modules linked in: xt_nat xt_tcpudp veth xt_conntrack nft_chain_nat xt_MASQUERADE nf_nat nf_conntrack_netlink nf_conntrack nf_defrag_ipv6 nf_defrag_ipv4 xfrm_user xfrm_algo xt_addrtype nft_compat nf_tables nfnetlink br_netfilter bridge rfkill quota_v2 quota_tree snd_soc_hdmi_codec snd_soc_rockchip_i2s snd_soc_core hantro_vpu rockchip_vdec(C) snd_compress v4l2_vp9 leds_pwm videobuf2_dma_contig rockchip_rga v4l2_h264 videobuf2_dma_sg v4l2_mem2mem videobuf2_memops snd_pcm_dmaengine pwm_fan snd_pcm videobuf2_v4l2 gpio_charger videobuf2_common snd_timer videodev panfrost gpu_sched snd mc drm_shmem_helper rockchip_rng rng_core soundcore fusb302 sg tcpm typec lz4hc lz4 gpio_beeper cpufreq_dt zram softdog ledtrig_netdev lm75 nfsd auth_rpcgss nfs_acl lockd grace sunrpc ip_tables x_tables autofs4 raid10 raid0 multipath linear raid1 dm_raid raid456 async_raid6_recov async_memcpy async_pq async_xor async_tx md_mod dm_mod realtek dwmac_rk stmmac_platform stmmac pcs_xpcs adc_keys [ 510.800061] CPU: 4 PID: 0 Comm: swapper/4 Tainted: G C 6.1.50-current-rockchip64 #3 [ 510.800866] Hardware name: Helios64 (DT) [ 510.801219] pstate: 600000c5 (nZCv daIF -PAN -UAO -TCO -DIT -SSBS BTYPE=--) [ 510.801840] pc : ct_kernel_enter.constprop.0+0xb8/0x180 [ 510.802323] lr : ct_kernel_enter.constprop.0+0xa8/0x180 [ 510.802794] sp : ffff800009eebd80 [ 510.803094] x29: ffff800009eebd80 x28: 0000000000000000 x27: 0000000000000000 [ 510.803739] x26: ffff000000761e00 x25: ffff800009474298 x24: ffff800009a3dc70 [ 510.804382] x23: fffe800100ee71e0 x22: ffff8000097668f0 x21: ffff8000094ea818 [ 510.805023] x20: 0000000000000000 x19: ffff8000097668f0 x18: 0000000000000000 [ 510.805664] x17: 0000000000000000 x16: ffff0000f7765f00 x15: 0000000000000000 [ 510.806306] x14: 0000000000000001 x13: 00000000000001ef x12: 0000000000000001 [ 510.806946] x11: 0000000000000000 x10: 0000000000000a90 x9 : ffff800009eebd50 [ 510.807587] x8 : ffff0000007628f0 x7 : 0000000000000000 x6 : 00000002f5f32d3a [ 510.808228] x5 : 00ffffffffffffff x4 : 0000000000152374 x3 : ffff800009757008 [ 510.808870] x2 : ffff000000761e00 x1 : ffff8000094868b0 x0 : 0000000000000001 [ 510.809510] Call trace: [ 510.809733] ct_kernel_enter.constprop.0+0xb8/0x180 [ 510.810177] ct_idle_exit+0x1c/0x30 [ 510.810498] default_idle_call+0x48/0x17c [ 510.810864] do_idle+0x23c/0x2b0 [ 510.811164] cpu_startup_entry+0x28/0x30 [ 510.811521] secondary_start_kernel+0x124/0x150 [ 510.811934] __secondary_switched+0xb0/0xb4 [ 510.812322] Code: f8605b00 b8606ac4 d503201f d2800020 (f90006e0) [ 510.812868] ---[ end trace 0000000000000000 ]--- [ 510.813283] Kernel panic - not syncing: Attempted to kill the idle task! [ 510.813877] SMP: stopping secondary CPUs [ 510.814234] Kernel Offset: disabled [ 510.814548] CPU features: 0x40000,20834084,0000421b [ 510.814987] Memory Limit: none [ 510.815273] Rebooting in 90 seconds.. Someone have ideas to have this fixed ? Where to report this problem ? Where to have help to get more informations ? Thank you Note : I have some programming skilled (and debugging), but no kernel development experience.
-
Dear to all, I'm new on linux environment so be patience with me. I have a helios64 unit with installed Openmediavault 6. When I reboot or turn-off helios64 (both from webgui interface that from power button) the hard disk ( 2 wd60efrx) make a cute sound from head. How can I check that heads are parked correctly? I don't want damage my hard disks Best regards
-
So I did the upgrade to OMV6 (and associated kernel update Linux 5.15.93-rockchip64). Now in the mornings or after long periods of no interaction, the Helios enters an unresponsive state where none of the docker containers respond and I can no longer ssh in. There is still some sporadic noise comming from hard drives doing things and lights on the front are showing it's not completely frozen. I suspect it's attempting to enter some kind of suspend / hibernate state that is not appropriate for this system. Which would be the appropriate log file to go hunting for answers for sleep/hibernate issues on Armbian? And what would be the recommended way to configure the available sleep options? Thanks.
-
Dear Forum, I am using a Helios64 with armbian Debian 10 (Buster) Linux-Kernel 5.15.52 and OMV 5.6.26-1. If I want to have further Updates from OMV I need to upgrade to Debian 11, because OMV6 isn't compatible to Buster. Any recomendations how I should upgrade? The H64-System is on a SDD. Should I try a cli system upgrade or installing everything new with a bullseye image, if this is available (Where?)? Best wishes, Greg
-
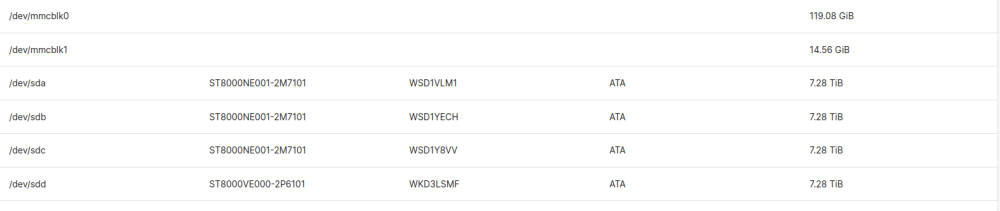
Hi, I had to change the Rack 1 HDD because I got an email telling me that this disk was broken. So I ordered new discs to make my replacement. When I put my new disk my problem started. For information my old disk was perfectly visible before I changed it and the led was functional too. I have a strange problem and I'm afraid it's hardware. Currently I have Rack 1 (HDD 1) which no longer detects my disks, there are no more LEDs lighting up, we can clearly hear the HDD lighting up, but it is not visible in the CLI and not via the WebUI. Im using OMV 6.x with kernel 5.15.89 (current) stable RAID 6 with 5 x 8To Have try 2 new HDD in Rack 1 KO Have try to reinstall armbian & omv KO Have you ever had this problem ? Could it be a software problem? Screens : (Only 4 HDD missing /dev/sde) armbianmonitor : http://ix.io/4oQB dmesg : https://paste.yunohost.org/sefecotame.vbs lsblk : "/dev/sde" is missing sda 8:0 0 7.3T 0 disk └─md127 9:127 0 21.8T 0 raid6 sdb 8:16 0 7.3T 0 disk └─md127 9:127 0 21.8T 0 raid6 sdc 8:32 0 7.3T 0 disk └─md127 9:127 0 21.8T 0 raid6 sdd 8:48 0 7.3T 0 disk └─md127 9:127 0 21.8T 0 raid6 Best Regards
-
Getting free() invalid pointer issue when installing / using python3. Could be dpkg issue as well ! When I did sudo apt update && sudo apt upgrade, it happened and hence I tried to reinstall. This issue occurs when trying to manage it with ansible as well. I think something might be wrong with the latest python. Board: Helios64 (I know, I know CSC) Chipset: RK3399 Apt install logs: Reading package lists... Done Building dependency tree... Done Reading state information... Done 0 upgraded, 0 newly installed, 2 reinstalled, 0 to remove and 0 not upgraded. Need to get 0 B/472 kB of archives. After this operation, 0 B of additional disk space will be used. (Reading database ... 44574 files and directories currently installed.) Preparing to unpack .../python3-pkg-resources_59.6.0-1.2ubuntu0.22.04.1_all.deb ... double free or corruption (out) Aborted dpkg: warning: old python3-pkg-resources package pre-removal script subprocess returned error exit status 134 dpkg: trying script from the new package instead ... dpkg: ... it looks like that went OK Unpacking python3-pkg-resources (59.6.0-1.2ubuntu0.22.04.1) over (59.6.0-1.2ubuntu0.22.04.1) ... Preparing to unpack .../python3-setuptools_59.6.0-1.2ubuntu0.22.04.1_all.deb ... Unpacking python3-setuptools (59.6.0-1.2ubuntu0.22.04.1) over (59.6.0-1.2ubuntu0.22.04.1) ... Setting up python3-pkg-resources (59.6.0-1.2ubuntu0.22.04.1) ... Setting up python3-setuptools (59.6.0-1.2ubuntu0.22.04.1) ... free(): invalid pointer Aborted dpkg: error processing package python3-setuptools (--configure): installed python3-setuptools package post-installation script subprocess returned error exit status 134 Errors were encountered while processing: python3-setuptools E: Sub-process /usr/bin/dpkg returned an error code (1) Ansible logs: ansible_facts: {} failed_modules: ansible.legacy.setup: ansible_facts: discovered_interpreter_python: /usr/bin/python3 failed: true module_stderr: |- free(): invalid pointer Aborted module_stdout: '' msg: |- MODULE FAILURE See stdout/stderr for the exact error rc: 134 msg: |- The following modules failed to execute: ansible.legacy.setup
-
 Hello, when i installed the helios64 initially i had the problem with the fans spinning at 100% (or really loud) and i solved it somehow. It was working fine with the fans spinning for one second when starting and shutting down the device. Now i finally updated the NAS with sudo apt update sudo apt upgrade sudo omv-release-upgrade sudo reboot and after the reboot the fans are now spinning really loud again all the time. Is anyone aware of an easy solution or a quick fix? Someone else had the same problem at https://forum.openmediavault.org/index.php?thread%2F42550-fans-go-on-full-and-stay-there-after-doing-an-update-in-omv-web-control-panel-he%2F= but it seems he either did not solve it or he just forgot to report back. I'm not sure if is related to my problem. alking about changing the fans but mentions the PWM Fan control again. On reddit someone mentions these settings again. I checked and my fancontrol settings seem to be identically or pretty close. In another reddit thread it was mentioned to "I went to armbian-config => System => CPU, set minimum and maximum CPU speed at 1200000 and set "governor" to "performance".". But its just "Fan too loud" and not "Fan spinning at 100%" So, i wanted to ask you guys if you know a fix for that problem 😕
Hello, when i installed the helios64 initially i had the problem with the fans spinning at 100% (or really loud) and i solved it somehow. It was working fine with the fans spinning for one second when starting and shutting down the device. Now i finally updated the NAS with sudo apt update sudo apt upgrade sudo omv-release-upgrade sudo reboot and after the reboot the fans are now spinning really loud again all the time. Is anyone aware of an easy solution or a quick fix? Someone else had the same problem at https://forum.openmediavault.org/index.php?thread%2F42550-fans-go-on-full-and-stay-there-after-doing-an-update-in-omv-web-control-panel-he%2F= but it seems he either did not solve it or he just forgot to report back. I'm not sure if is related to my problem. alking about changing the fans but mentions the PWM Fan control again. On reddit someone mentions these settings again. I checked and my fancontrol settings seem to be identically or pretty close. In another reddit thread it was mentioned to "I went to armbian-config => System => CPU, set minimum and maximum CPU speed at 1200000 and set "governor" to "performance".". But its just "Fan too loud" and not "Fan spinning at 100%" So, i wanted to ask you guys if you know a fix for that problem 😕 -
Fresh build edge bullseye image with kernel Linux helios 5.18.0-rockchip64 #trunk SMP PREEMPT Sun May 29 20:19:27 EEST 2022 aarch64 GNU/Linux fancontrol not work, because there no /dev/fan devices How to get fancontrol back to work?