Search the Community
Showing results for tags 'helios64'.
-
 The most current download images for Helios64 are now all provided with linux 6.18.xx. I downloaded a minimal image and checked the dtb: it would not appear to contain the opp-microvolt patch that made Helios64 finally stable. So for the ones who have stability issues again on Helios64, I attached the patched dtb compiled for linux 6.18.xx using the exact same opp-microvolt values as in the previous dtb versions I compiled for linux 6.6 and 6.12. The current linux deb files can be downloaded from beta.armbian.com, the linux 6.18.18 deb files I used can be downloaded from here (to be installed with 'dpkg -i linux*'). In order to install the dtb, simply unzip it, copy it into the proper location, update initramfs and reboot: # install the dtb with the opp-microvolt patch: unzip rk3399-kobol-helios64.dtb-6.18.18-opp.zip cp rk3399-kobol-helios64.dtb-6.18.18-opp /boot/dtb/rockchip/rk3399-kobol-helios64.dtb update-initramfs -u reboot rk3399-kobol-helios64.dtb-6.18.18-opp.zip
The most current download images for Helios64 are now all provided with linux 6.18.xx. I downloaded a minimal image and checked the dtb: it would not appear to contain the opp-microvolt patch that made Helios64 finally stable. So for the ones who have stability issues again on Helios64, I attached the patched dtb compiled for linux 6.18.xx using the exact same opp-microvolt values as in the previous dtb versions I compiled for linux 6.6 and 6.12. The current linux deb files can be downloaded from beta.armbian.com, the linux 6.18.18 deb files I used can be downloaded from here (to be installed with 'dpkg -i linux*'). In order to install the dtb, simply unzip it, copy it into the proper location, update initramfs and reboot: # install the dtb with the opp-microvolt patch: unzip rk3399-kobol-helios64.dtb-6.18.18-opp.zip cp rk3399-kobol-helios64.dtb-6.18.18-opp /boot/dtb/rockchip/rk3399-kobol-helios64.dtb update-initramfs -u reboot rk3399-kobol-helios64.dtb-6.18.18-opp.zip -
Hello everybody, With 6.18.10-current-rockchip64 and rk3399-kobol-helios64.dtb-6.18.18-opp dtb file, Ok With 6.18.35-current-rockchip64 and overlay helios64 patch with armbian-config, Ko With 6.18.35-current-rockchip64 and k3399-kobol-helios64.dtb-6.18.18-opp dtb file, Ko The crash is random... sometime crash: - At the boot with red system light blinking - At the opening of my LUKS ciffers drives - At a high cpu load - With nothing special, all led are blue, system blinking but network and ssh is Ko Is it possible to explain me how to see the problem or how to have log because I am in blind to have more details ? Is it possible to explain me how to pass to the last 6.18.36 kernel to seen if it is better than 6.18.35 ? Thanks a lot.
-
Today I upgraded my Helios64, and after reboot it didn't come back. (Waited for 5 minutes or so) After connecting a serial cable (via the USB-C connector), and rebooting, I saw a normal bootloader log (as far as I can see), but no kernel log, just a repeated 'ERROR: rockchip_plat_sip_handler: unhandled SMC (0x82000003)'. I rebooted again, to create a bootlog file, and I saw the same. Then suddenly, after a minute or so, I saw network activity, and my Helios64 was back. Now I have 3 questions. 1) Why didn't it boot twice, and then succeeded? 2) Why is there no kernel bootlog? 3) What is an unhandled SMC? The log ended with ERROR: rockchip_plat_sip_handler: unhandled SMC (0x82000003) ERROR: rockchip_plat_sip_handler: unhandled SMC (0x82000003) p104^Gp104^G Armbian 26.5.1 trixie ttyS2 helios64 login: So apparently the serial port is ttyS2. dmesg gave me this info: sudo dmesg | grep tty [ 0.000000] Kernel command line: root=UUID=d03fc106-73e9-4465-89a6-b23dbd26eddd rootwait rootfstype=btrfs splash=verbose console=ttyS2,1500000 console=tty1 consoleblank=0 loglevel=1 ubootpart= usb-storage.quirks=0x2537:0x1066:u,0x2537:0x1068:u cgroup_enable=cpuset cgroup_memory=1 cgroup_enable=memory [ 0.001587] printk: legacy console [tty1] enabled [ 1.986600] ff180000.serial: ttyS0 at MMIO 0xff180000 (irq = 31, base_baud = 1500000) is a 16550A [ 1.988766] ff1a0000.serial: ttyS2 at MMIO 0xff1a0000 (irq = 32, base_baud = 1500000) is a 16550A [ 1.988911] printk: legacy console [ttyS2] enabled [ 7.930510] systemd[1]: Created slice system-getty.slice - Slice /system/getty. [ 7.934926] systemd[1]: Created slice system-serial\x2dgetty.slice - Slice /system/serial-getty. [ 7.938724] systemd[1]: Expecting device dev-ttyS2.device - /dev/ttyS2... [ 8.771412] systemd[1]: Found device dev-ttyS2.device - /dev/ttyS2. Is it normal that there are 2 legacy consoles enabled? minicom.cap
-
Current build hangs whilst booting , any ideas anyone ? DDR Version 1.25 20210517 In soft reset SRX channel 0 CS = 0 MR0=0x18 MR4=0x1 MR5=0x1 MR8=0x10 MR12=0x72 MR14=0x72 MR18=0x0 MR19=0x0 MR24=0x8 MR25=0x0 channel 1 CS = 0 MR0=0x18 MR4=0x1 MR5=0x1 MR8=0x10 MR12=0x72 MR14=0x72 MR18=0x0 MR19=0x0 MR24=0x8 MR25=0x0 channel 0 training pass! channel 1 training pass! change freq to 416MHz 0,1 Channel 0: LPDDR4,416MHz Bus Width=32 Col=10 Bank=8 Row=16 CS=1 Die Bus-Width=16 Size=2048MB Channel 1: LPDDR4,416MHz Bus Width=32 Col=10 Bank=8 Row=16 CS=1 Die Bus-Width=16 Size=2048MB 256B stride channel 0 CS = 0 MR0=0x18 MR4=0x1 MR5=0x1 MR8=0x10 MR12=0x72 MR14=0x72 MR18=0x0 MR19=0x0 MR24=0x8 MR25=0x0 channel 1 CS = 0 MR0=0x18 MR4=0x1 MR5=0x1 MR8=0x10 MR12=0x72 MR14=0x72 MR18=0x0 MR19=0x0 MR24=0x8 MR25=0x0 channel 0 training pass! channel 1 training pass! channel 0, cs 0, advanced training done channel 1, cs 0, advanced training done change freq to 856MHz 1,0 ch 0 ddrconfig = 0x101, ddrsize = 0x40 ch 1 ddrconfig = 0x101, ddrsize = 0x40 pmugrf_os_reg[2] = 0x32C1F2C1, stride = 0xD ddr_set_rate to 328MHZ ddr_set_rate to 666MHZ ddr_set_rate to 928MHZ channel 0, cs 0, advanced training done channel 1, cs 0, advanced training done ddr_set_rate to 416MHZ, ctl_index 0 ddr_set_rate to 856MHZ, ctl_index 1 support 416 856 328 666 928 MHz, current 856MHz OUT U-Boot SPL 2022.07_armbian-2022.07-Se092-P3fcd-H28b4-V0d63-Bbf55-R448a (Dec 16 2025 - 03:12:11 +0000) Trying to boot from MMC1 mmc_load_image_raw_sector: mmc block read error Trying to boot from SPI Trying to boot from MMC1 NOTICE: BL31: v2.13.0(release):armbian NOTICE: BL31: Built : 04:23:02, Nov 24 2025 INFO: GICv3 with legacy support detected. INFO: ARM GICv3 driver initialized in EL3 INFO: Maximum SPI INTID supported: 287 INFO: plat_rockchip_pmu_init(1624): pd status 3e INFO: BL31: Initializing runtime services INFO: BL31: Preparing for EL3 exit to normal world INFO: Entry point address = 0x200000 INFO: SPSR = 0x3c9 U-Boot 2022.07_armbian-2022.07-Se092-P3fcd-H28b4-V0d63-Bbf55-R448a (Dec 16 2025 - 03:12:11 +0000) SoC: Rockchip rk3399 Reset cause: RST DRAM: 3.9 GiB PMIC: RK808 Core: 339 devices, 31 uclasses, devicetree: separate SF: Detected w25q128 with page size 256 Bytes, erase size 4 KiB, total 16 MiB MMC: mmc@fe320000: 1, mmc@fe330000: 0 Loading Environment from MMC... *** Warning - bad CRC, using default environment In: serial Out: serial Err: serial Model: Helios64 Revision: 1.2 - 4GB non ECC Net: dw_dm_mdio_init: mdio node is missing, registering legacy mdio busNo ethernet found. scanning bus for devices... Hit any key to stop autoboot: 0 switch to partitions #0, OK mmc1 is current device Scanning mmc 1:1... Found U-Boot script /boot/boot.scr 3906 bytes read in 5 ms (762.7 KiB/s) ## Executing script at 00500000 Boot script loaded from mmc 1:1 299 bytes read in 5 ms (57.6 KiB/s) 24731811 bytes read in 1050 ms (22.5 MiB/s) 39770624 bytes read in 1683 ms (22.5 MiB/s) 90994 bytes read in 20 ms (4.3 MiB/s) 725 bytes read in 6 ms (117.2 KiB/s) Applying user provided DT overlay rockchip-rk3399-op1-opp.dtbo 780 bytes read in 5 ms (152.3 KiB/s) Applying user provided DT overlay rockchip-rk3399-l2-cache.dtbo 2825 bytes read in 41 ms (66.4 KiB/s) Applying kernel provided DT fixup script (rockchip-fixup.scr) ## Executing script at 09000000 Trying kaslrseed command... Info: Unknown command can be safely ignored since kaslrseed does not apply to all boards. Unknown command 'kaslrseed' - try 'help' Moving Image from 0x2080000 to 0x2200000, end=48b0000 ## Loading init Ramdisk from Legacy Image at 06000000 ... Image Name: uInitrd Image Type: AArch64 Linux RAMDisk Image (gzip compressed) Data Size: 24731747 Bytes = 23.6 MiB Load Address: 00000000 Entry Point: 00000000 Verifying Checksum ... OK ## Flattened Device Tree blob at 01f00000 Booting using the fdt blob at 0x1f00000 Loading Ramdisk to f4747000, end f5edd063 ... OK Loading Device Tree to 00000000f46c8000, end 00000000f4746fff ... OK Starting kernel ... [ 0.000000] Booting Linux on physical CPU 0x0000000000 [0x410fd034] [ 0.000000] Linux version 6.18.10-current-rockchip64 (build@armbian) (aarch64-linux-gnu-gcc (Ubuntu 13.3.0-6ubuntu2~24.04) 13.3.0, GNU ld (GNU Binutils for Ubuntu) 2.42) #2 SMP PREEMPT Wed Feb 11 12:42:01 UTC 2026 [ 0.000000] KASLR disabled due to lack of seed [ 0.000000] Machine model: Kobol Helios64 [ 0.000000] printk: debug: ignoring loglevel setting. [ 0.000000] efi: UEFI not found. [ 0.000000] OF: reserved mem: Reserved memory: No reserved-memory node in the DT [ 0.000000] NUMA: Faking a node at [mem 0x0000000000200000-0x00000000f7ffffff] [ 0.000000] NODE_DATA(0) allocated [mem 0xf77c6380-0xf77c8b3f] [ 0.000000] Zone ranges: [ 0.000000] DMA [mem 0x0000000000200000-0x00000000f7ffffff] [ 0.000000] DMA32 empty [ 0.000000] Normal empty [ 0.000000] Movable zone start for each node [ 0.000000] Early memory node ranges [ 0.000000] node 0: [mem 0x0000000000200000-0x00000000f7ffffff] [ 0.000000] Initmem setup node 0 [mem 0x0000000000200000-0x00000000f7ffffff] [ 0.000000] On node 0, zone DMA: 512 pages in unavailable ranges [ 0.000000] cma: Reserved 128 MiB at 0x00000000e8800000 [ 0.000000] psci: probing for conduit method from DT. [ 0.000000] psci: PSCIv1.1 detected in firmware. [ 0.000000] psci: Using standard PSCI v0.2 function IDs [ 0.000000] psci: MIGRATE_INFO_TYPE not supported. [ 0.000000] psci: SMC Calling Convention v1.5 [ 0.000000] percpu: Embedded 34 pages/cpu s100376 r8192 d30696 u139264 [ 0.000000] pcpu-alloc: s100376 r8192 d30696 u139264 alloc=34*4096 [ 0.000000] pcpu-alloc: [0] 0 [0] 1 [0] 2 [0] 3 [0] 4 [0] 5 [ 0.000000] Detected VIPT I-cache on CPU0 [ 0.000000] CPU features: detected: GICv3 CPU interface [ 0.000000] CPU features: detected: ARM erratum 845719 [ 0.000000] alternatives: applying boot alternatives [ 0.000000] Kernel command line: root=UUID=0a68fe65-7fd3-47ab-b68f-ef2fddb464c9 rootwait rootfstype=ext4 splash=verbose console=ttyS2,1500000 console=tty1 consoleblank=0 loglevel=7 ubootpart=7a8c3cb1-01 usb-storage.quirks=0x2537:0x1066:u,0x2537:0x1068:u earlyprintk ignore_loglevel cgroup_enable=cpuset cgroup_memory=1 cgroup_enable=memory [ 0.000000] Unknown kernel command line parameters "earlyprintk splash=verbose ubootpart=7a8c3cb1-01 cgroup_enable=memory cgroup_memory=1", will be passed to user space. [ 0.000000] printk: log buffer data + meta data: 262144 + 917504 = 1179648 bytes [ 0.000000] Dentry cache hash table entries: 524288 (order: 10, 4194304 bytes, linear) [ 0.000000] Inode-cache hash table entries: 262144 (order: 9, 2097152 bytes, linear) [ 0.000000] software IO TLB: SWIOTLB bounce buffer size adjusted to 3MB [ 0.000000] software IO TLB: area num 8. [ 0.000000] software IO TLB: mapped [mem 0x00000000f6ce3000-0x00000000f70e3000] (4MB) [ 0.000000] Fallback order for Node 0: 0 [ 0.000000] Built 1 zonelists, mobility grouping on. Total pages: 1015296 [ 0.000000] Policy zone: DMA [ 0.000000] mem auto-init: stack:all(zero), heap alloc:on, heap free:off [ 0.000000] SLUB: HWalign=64, Order=0-3, MinObjects=0, CPUs=6, Nodes=1 [ 0.000000] ftrace: allocating 55125 entries in 216 pages [ 0.000000] ftrace: allocated 216 pages with 4 groups [ 0.000000] rcu: Preemptible hierarchical RCU implementation. [ 0.000000] rcu: RCU event tracing is enabled. [ 0.000000] rcu: RCU restricting CPUs from NR_CPUS=256 to nr_cpu_ids=6. [ 0.000000] Trampoline variant of Tasks RCU enabled. [ 0.000000] Rude variant of Tasks RCU enabled. [ 0.000000] Tracing variant of Tasks RCU enabled. [ 0.000000] rcu: RCU calculated value of scheduler-enlistment delay is 25 jiffies. [ 0.000000] rcu: Adjusting geometry for rcu_fanout_leaf=16, nr_cpu_ids=6 [ 0.000000] RCU Tasks: Setting shift to 3 and lim to 1 rcu_task_cb_adjust=1 rcu_task_cpu_ids=6. [ 0.000000] RCU Tasks Rude: Setting shift to 3 and lim to 1 rcu_task_cb_adjust=1 rcu_task_cpu_ids=6. [ 0.000000] RCU Tasks Trace: Setting shift to 3 and lim to 1 rcu_task_cb_adjust=1 rcu_task_cpu_ids=6. [ 0.000000] NR_IRQS: 64, nr_irqs: 64, preallocated irqs: 0 [ 0.000000] GICv3: GIC: Using split EOI/Deactivate mode [ 0.000000] GIC: enabling workaround for GICv3: Insecure RK3399 integration [ 0.000000] GICv3: 256 SPIs implemented [ 0.000000] GICv3: 0 Extended SPIs implemented [ 0.000000] Root IRQ handler: gic_handle_irq [ 0.000000] GICv3: GICv3 features: 16 PPIs [ 0.000000] GICv3: Broken GIC integration, security disabled [ 0.000000] GICv3: GICD_CTLR.DS=1, SCR_EL3.FIQ=0 [ 0.000000] GICv3: CPU0: found redistributor 0 region 0:0x00000000fef00000 [ 0.000000] ITS [mem 0xfee20000-0xfee3ffff] [ 0.000000] ITS@0x00000000fee20000: allocated 65536 Devices @600000 (flat, esz 8, psz 64K, shr 0) [ 0.000000] ITS: using cache flushing for cmd queue [ 0.000000] GICv3: using LPI property table @0x0000000000680000 [ 0.000000] GIC: using cache flushing for LPI property table [ 0.000000] GICv3: CPU0: using allocated LPI pending table @0x0000000000690000 [ 0.000000] GICv3: GIC: PPI partition interrupt-partition-0[0] { /cpus/cpu@0[0] /cpus/cpu@1[1] /cpus/cpu@2[2] /cpus/cpu@3[3] } [ 0.000000] GICv3: GIC: PPI partition interrupt-partition-1[1] { /cpus/cpu@100[4] /cpus/cpu@101[5] } [ 0.000000] rcu: srcu_init: Setting srcu_struct sizes based on contention. [ 0.000000] arch_timer: cp15 timer running at 24.00MHz (phys). [ 0.000000] clocksource: arch_sys_counter: mask: 0xffffffffffffff max_cycles: 0x588fe9dc0, max_idle_ns: 440795202592 ns [ 0.000001] sched_clock: 56 bits at 24MHz, resolution 41ns, wraps every 4398046511097ns [ 0.001626] Console: colour dummy device 80x25 [ 0.001652] printk: legacy console [tty1] enabled [ 0.003229] Calibrating delay loop (skipped), value calculated using timer frequency.. 48.00 BogoMIPS (lpj=96000) [ 0.003282] pid_max: default: 32768 minimum: 301 [ 0.003476] LSM: initializing lsm=capability,yama,apparmor [ 0.003600] Yama: becoming mindful. [ 0.004097] AppArmor: AppArmor initialized [ 0.004276] Mount-cache hash table entries: 8192 (order: 4, 65536 bytes, linear) [ 0.004337] Mountpoint-cache hash table entries: 8192 (order: 4, 65536 bytes, linear) [ 0.009162] rcu: Hierarchical SRCU implementation. [ 0.009217] rcu: Max phase no-delay instances is 1000. [ 0.009735] Timer migration: 1 hierarchy levels; 8 children per group; 1 crossnode level [ 0.011454] EFI services will not be available. [ 0.012131] smp: Bringing up secondary CPUs ... [ 0.013222] Detected VIPT I-cache on CPU1 [ 0.013531] GICv3: CPU1: found redistributor 1 region 0:0x00000000fef20000 [ 0.013558] GICv3: CPU1: using allocated LPI pending table @0x00000000006a0000 [ 0.013631] CPU1: Booted secondary processor 0x0000000001 [0x410fd034] [ 0.014865] Detected VIPT I-cache on CPU2 [ 0.015141] GICv3: CPU2: found redistributor 2 region 0:0x00000000fef40000 [ 0.015164] GICv3: CPU2: using allocated LPI pending table @0x00000000006b0000 [ 0.015216] CPU2: Booted secondary processor 0x0000000002 [0x410fd034] [ 0.016480] Detected VIPT I-cache on CPU3 [ 0.016759] GICv3: CPU3: found redistributor 3 region 0:0x00000000fef60000 [ 0.016782] GICv3: CPU3: using allocated LPI pending table @0x00000000006c0000 [ 0.016833] CPU3: Booted secondary processor 0x0000000003 [0x410fd034] [ 0.018025] CPU features: detected: Spectre-v2 [ 0.018042] CPU features: detected: Spectre-v3a [ 0.018054] CPU features: detected: Spectre-BHB [ 0.018065] CPU features: detected: ARM erratum 1742098 [ 0.018075] CPU features: detected: ARM errata 1165522, 1319367, or 1530923 [ 0.018083] Detected PIPT I-cache on CPU4 [ 0.018332] GICv3: CPU4: found redistributor 100 region 0:0x00000000fef80000 [ 0.018352] GICv3: CPU4: using allocated LPI pending table @0x00000000006d0000 [ 0.018400] CPU4: Booted secondary processor 0x0000000100 [0x410fd082] [ 0.019532] Detected PIPT I-cache on CPU5 [ 0.019765] GICv3: CPU5: found redistributor 101 region 0:0x00000000fefa0000 [ 0.019785] GICv3: CPU5: using allocated LPI pending table @0x00000000006e0000 [ 0.019825] CPU5: Booted secondary processor 0x0000000101 [0x410fd082] [
-
 If I transfer from Helios64 2.5Gbit Port to a client 2.5Gbit port I'll got a very slow transfer rate (Helios -> client around 200Mbit/s), vice versa full speed, switch is 2.5Gbit (Rj45 ethernet Cat7 cable).Testet with iperf. The switch monitoring indicates always 2 errors. I know about the Hardware issue of Lan-Port2, but it only effect 1Gbit transfer. Nevertheless in the Network are also mixed with 1Gbit clients. Is there anything I'll can try to get full 2.5Gbit speed?
If I transfer from Helios64 2.5Gbit Port to a client 2.5Gbit port I'll got a very slow transfer rate (Helios -> client around 200Mbit/s), vice versa full speed, switch is 2.5Gbit (Rj45 ethernet Cat7 cable).Testet with iperf. The switch monitoring indicates always 2 errors. I know about the Hardware issue of Lan-Port2, but it only effect 1Gbit transfer. Nevertheless in the Network are also mixed with 1Gbit clients. Is there anything I'll can try to get full 2.5Gbit speed? -
Hello, I updated to Armbian 26.2.1 trixie installaed on emmc. If I poweroff the nas and power on again it does't work, but if I attach an usb cable to the console it works. I think the problem must be related to the u-boot part.
-
 Hi everybody, I running Helios64 with kernel 6.12.58 since a long time and the prahal dtb file rk3399-kobol-helios64.dtb-6.12.xx-L2-hs400-opp and my helios64 work well. Today, Armbian upgrade to 6.18.10 kernel. Is this update use the same change or patch like in rk3399-kobol-helios64.dtb-6.12.xx-L2-hs400-opp ? Is rk3399-kobol-helios64.dtb-6.12.xx-L2-hs400-opp work with 6..18.10 kernel ? Is I must to downgrade to 6.12.58 kernel with rk3399-kobol-helios64.dtb-6.12.xx-L2-hs400-opp and freeze at this kernel version ? Thanks for answer.
Hi everybody, I running Helios64 with kernel 6.12.58 since a long time and the prahal dtb file rk3399-kobol-helios64.dtb-6.12.xx-L2-hs400-opp and my helios64 work well. Today, Armbian upgrade to 6.18.10 kernel. Is this update use the same change or patch like in rk3399-kobol-helios64.dtb-6.12.xx-L2-hs400-opp ? Is rk3399-kobol-helios64.dtb-6.12.xx-L2-hs400-opp work with 6..18.10 kernel ? Is I must to downgrade to 6.12.58 kernel with rk3399-kobol-helios64.dtb-6.12.xx-L2-hs400-opp and freeze at this kernel version ? Thanks for answer. -
 Hey guys, So I wanted to update the OS on my NAS to patch the Copy Fail vulnerability today. I installed everything, I also did an apt-upgrade (not a full one) to make sure my kernel was as up to date as I could get it, and I also updated the initramfs, too. Now when I boot up the Kobol, I can hear the disks spinning up after a few seconds upon powering up, they make an odd noise and then just stop. The LEDs on the front panel also no longer show blue anymore, and `fdisk -l` no longer shows anything. I know for a fact these HDDs are not dead. They have worked perfectly fine before the upgrade, and the SATA pins look perfectly clean. I even tried swapping from bays 1 and 2 to 3 and 4 and still no dice. I may go through and attach serial or dmesg output. But yeah, nothing much about "ata" shows up in `dmesg` after booting.
Hey guys, So I wanted to update the OS on my NAS to patch the Copy Fail vulnerability today. I installed everything, I also did an apt-upgrade (not a full one) to make sure my kernel was as up to date as I could get it, and I also updated the initramfs, too. Now when I boot up the Kobol, I can hear the disks spinning up after a few seconds upon powering up, they make an odd noise and then just stop. The LEDs on the front panel also no longer show blue anymore, and `fdisk -l` no longer shows anything. I know for a fact these HDDs are not dead. They have worked perfectly fine before the upgrade, and the SATA pins look perfectly clean. I even tried swapping from bays 1 and 2 to 3 and 4 and still no dice. I may go through and attach serial or dmesg output. But yeah, nothing much about "ata" shows up in `dmesg` after booting. -
Hello Everyone, Unfortunately my helios64 is not glowing any power LED. As soon as I connect the power supply it only shows a blinking orange LED light, that is basically for the battery status. My power supply is perfectly fine and even I have tried using with the ATX power supply same result. Does anyone face this issue and please help me to get my board working again. Thanks!

-
 First of all thanks to the people maintaining armbian for helios64. I recently upgraded (well I reinstalled) to trixie and everything mostly runs stable for me. However I have a problem with the 2.5GB adapter. It is connected to a 2.5GB switch and when for example running iperf3 I get proper results close to 2.5 GBit. So in general it seems to be running ok. I have a DLNA server (minidlna) running on that machine and when I stream from my TV (streaming via VLC from my laptop triggers the same problems) the network connection drops for a moment and works again after a few seconds (which you can guess is super annoying when watching something). I am not sure what exactly is triggering this. most of the time the network is super stable but during streaming I get hickups. This is what my kernel log spits out when this is happending: ``` Apr 09 17:45:54 hermann-walter kernel: xhci-hcd xhci-hcd.0.auto: Event TRB for slot 4 ep 3 with no TDs queued Apr 09 17:45:54 hermann-walter kernel: xhci-hcd xhci-hcd.0.auto: Event TRB for slot 4 ep 3 with no TDs queued Apr 09 17:45:54 hermann-walter kernel: xhci-hcd xhci-hcd.0.auto: Event TRB for slot 4 ep 3 with no TDs queued Apr 09 17:45:54 hermann-walter kernel: xhci-hcd xhci-hcd.0.auto: Event TRB for slot 4 ep 3 with no TDs queued Apr 09 17:45:54 hermann-walter kernel: xhci-hcd xhci-hcd.0.auto: Event dma 0x00000000053f8f10 for ep 3 status 1 not part of TD at 00000000053f8ed0 - 00000000053f8ed0 Apr 09 17:45:54 hermann-walter kernel: xhci-hcd xhci-hcd.0.auto: Event dma 0x00000000053f8f20 for ep 3 status 1 not part of TD at 00000000053f8ed0 - 00000000053f8ed0 Apr 09 17:45:54 hermann-walter kernel: xhci-hcd xhci-hcd.0.auto: Event dma 0x00000000053f8f30 for ep 3 status 1 not part of TD at 00000000053f8ed0 - 00000000053f8ed0 Apr 09 17:45:54 hermann-walter kernel: xhci-hcd xhci-hcd.0.auto: Event dma 0x00000000053f8f40 for ep 3 status 1 not part of TD at 00000000053f8ed0 - 00000000053f8ed0 Apr 09 17:45:54 hermann-walter kernel: xhci-hcd xhci-hcd.0.auto: Event dma 0x00000000053f8f50 for ep 3 status 1 not part of TD at 00000000053f8ed0 - 00000000053f8ed0 Apr 09 17:45:54 hermann-walter kernel: xhci-hcd xhci-hcd.0.auto: Event dma 0x00000000053f8f60 for ep 3 status 1 not part of TD at 00000000053f8ed0 - 00000000053f8ed0 Apr 09 17:45:54 hermann-walter kernel: xhci-hcd xhci-hcd.0.auto: Event dma 0x00000000053f8f70 for ep 3 status 1 not part of TD at 00000000053f8ed0 - 00000000053f8ed0 Apr 09 17:45:54 hermann-walter kernel: xhci-hcd xhci-hcd.0.auto: Event dma 0x00000000053f8f80 for ep 3 status 1 not part of TD at 00000000053f8ed0 - 00000000053f8ed0 Apr 09 17:45:54 hermann-walter kernel: xhci-hcd xhci-hcd.0.auto: Event dma 0x00000000053f8f90 for ep 3 status 1 not part of TD at 00000000053f8ed0 - 00000000053f8ed0 Apr 09 17:45:54 hermann-walter kernel: xhci-hcd xhci-hcd.0.auto: Event dma 0x00000000053f8fa0 for ep 3 status 1 not part of TD at 00000000053f8ed0 - 00000000053f8ed0 Apr 09 17:45:59 hermann-walter kernel: r8152 2-1.4:1.0 enx646266d00873: NETDEV WATCHDOG: CPU: 0: transmit queue 0 timed out 5152 ms Apr 09 17:45:59 hermann-walter kernel: r8152 2-1.4:1.0 enx646266d00873: Tx timeout Apr 09 17:46:00 hermann-walter kernel: r8152 2-1.4:1.0 enx646266d00873: Tx status -2 Apr 09 17:46:00 hermann-walter kernel: r8152 2-1.4:1.0 enx646266d00873: Tx status -2 Apr 09 17:46:00 hermann-walter kernel: r8152 2-1.4:1.0 enx646266d00873: Tx status -2 Apr 09 17:46:00 hermann-walter kernel: r8152 2-1.4:1.0 enx646266d00873: Tx status -2 Apr 09 17:46:02 hermann-walter kernel: r8152-cfgselector 2-1.4: reset SuperSpeed USB device number 3 using xhci-hcd ``` the usb related messages are not always there but the r8152 related messages are always there. I found a similar problem here: https://github.com/openwrt/openwrt/issues/22130 I tried replacing the firmware but that didn't help and I later found out that the helios64 uses a different firmware so that explains why it didn't help: ``` Apr 10 05:48:30 hermann-walter kernel: r8152 2-1.4:1.0: Loaded FW: rtl_nic/rtl8156a-2.fw, sha256: 7b50f4a307bde7b3f384935537c4d9705457fa42613eb0003ffbc4e19461a1e0 Apr 10 05:48:30 hermann-walter kernel: r8152 2-1.4:1.0: Loaded FW: rtl_nic/rtl8156a-2.fw, sha256: 7b50f4a307bde7b3f384935537c4d9705457fa42613eb0003ffbc4e19461a1e0 ``` does anybody know what is going on? I am quite sure that the problem wasn't there before the upgrade (but I might be mistaken because I only started observing the helios64 again after the upgrade. also it seems to be related to the amount of network traffic going on. i.e. lower bitrate streams seem to not trigger the problem). Streaming via the 1GBit NIC is working fine.
First of all thanks to the people maintaining armbian for helios64. I recently upgraded (well I reinstalled) to trixie and everything mostly runs stable for me. However I have a problem with the 2.5GB adapter. It is connected to a 2.5GB switch and when for example running iperf3 I get proper results close to 2.5 GBit. So in general it seems to be running ok. I have a DLNA server (minidlna) running on that machine and when I stream from my TV (streaming via VLC from my laptop triggers the same problems) the network connection drops for a moment and works again after a few seconds (which you can guess is super annoying when watching something). I am not sure what exactly is triggering this. most of the time the network is super stable but during streaming I get hickups. This is what my kernel log spits out when this is happending: ``` Apr 09 17:45:54 hermann-walter kernel: xhci-hcd xhci-hcd.0.auto: Event TRB for slot 4 ep 3 with no TDs queued Apr 09 17:45:54 hermann-walter kernel: xhci-hcd xhci-hcd.0.auto: Event TRB for slot 4 ep 3 with no TDs queued Apr 09 17:45:54 hermann-walter kernel: xhci-hcd xhci-hcd.0.auto: Event TRB for slot 4 ep 3 with no TDs queued Apr 09 17:45:54 hermann-walter kernel: xhci-hcd xhci-hcd.0.auto: Event TRB for slot 4 ep 3 with no TDs queued Apr 09 17:45:54 hermann-walter kernel: xhci-hcd xhci-hcd.0.auto: Event dma 0x00000000053f8f10 for ep 3 status 1 not part of TD at 00000000053f8ed0 - 00000000053f8ed0 Apr 09 17:45:54 hermann-walter kernel: xhci-hcd xhci-hcd.0.auto: Event dma 0x00000000053f8f20 for ep 3 status 1 not part of TD at 00000000053f8ed0 - 00000000053f8ed0 Apr 09 17:45:54 hermann-walter kernel: xhci-hcd xhci-hcd.0.auto: Event dma 0x00000000053f8f30 for ep 3 status 1 not part of TD at 00000000053f8ed0 - 00000000053f8ed0 Apr 09 17:45:54 hermann-walter kernel: xhci-hcd xhci-hcd.0.auto: Event dma 0x00000000053f8f40 for ep 3 status 1 not part of TD at 00000000053f8ed0 - 00000000053f8ed0 Apr 09 17:45:54 hermann-walter kernel: xhci-hcd xhci-hcd.0.auto: Event dma 0x00000000053f8f50 for ep 3 status 1 not part of TD at 00000000053f8ed0 - 00000000053f8ed0 Apr 09 17:45:54 hermann-walter kernel: xhci-hcd xhci-hcd.0.auto: Event dma 0x00000000053f8f60 for ep 3 status 1 not part of TD at 00000000053f8ed0 - 00000000053f8ed0 Apr 09 17:45:54 hermann-walter kernel: xhci-hcd xhci-hcd.0.auto: Event dma 0x00000000053f8f70 for ep 3 status 1 not part of TD at 00000000053f8ed0 - 00000000053f8ed0 Apr 09 17:45:54 hermann-walter kernel: xhci-hcd xhci-hcd.0.auto: Event dma 0x00000000053f8f80 for ep 3 status 1 not part of TD at 00000000053f8ed0 - 00000000053f8ed0 Apr 09 17:45:54 hermann-walter kernel: xhci-hcd xhci-hcd.0.auto: Event dma 0x00000000053f8f90 for ep 3 status 1 not part of TD at 00000000053f8ed0 - 00000000053f8ed0 Apr 09 17:45:54 hermann-walter kernel: xhci-hcd xhci-hcd.0.auto: Event dma 0x00000000053f8fa0 for ep 3 status 1 not part of TD at 00000000053f8ed0 - 00000000053f8ed0 Apr 09 17:45:59 hermann-walter kernel: r8152 2-1.4:1.0 enx646266d00873: NETDEV WATCHDOG: CPU: 0: transmit queue 0 timed out 5152 ms Apr 09 17:45:59 hermann-walter kernel: r8152 2-1.4:1.0 enx646266d00873: Tx timeout Apr 09 17:46:00 hermann-walter kernel: r8152 2-1.4:1.0 enx646266d00873: Tx status -2 Apr 09 17:46:00 hermann-walter kernel: r8152 2-1.4:1.0 enx646266d00873: Tx status -2 Apr 09 17:46:00 hermann-walter kernel: r8152 2-1.4:1.0 enx646266d00873: Tx status -2 Apr 09 17:46:00 hermann-walter kernel: r8152 2-1.4:1.0 enx646266d00873: Tx status -2 Apr 09 17:46:02 hermann-walter kernel: r8152-cfgselector 2-1.4: reset SuperSpeed USB device number 3 using xhci-hcd ``` the usb related messages are not always there but the r8152 related messages are always there. I found a similar problem here: https://github.com/openwrt/openwrt/issues/22130 I tried replacing the firmware but that didn't help and I later found out that the helios64 uses a different firmware so that explains why it didn't help: ``` Apr 10 05:48:30 hermann-walter kernel: r8152 2-1.4:1.0: Loaded FW: rtl_nic/rtl8156a-2.fw, sha256: 7b50f4a307bde7b3f384935537c4d9705457fa42613eb0003ffbc4e19461a1e0 Apr 10 05:48:30 hermann-walter kernel: r8152 2-1.4:1.0: Loaded FW: rtl_nic/rtl8156a-2.fw, sha256: 7b50f4a307bde7b3f384935537c4d9705457fa42613eb0003ffbc4e19461a1e0 ``` does anybody know what is going on? I am quite sure that the problem wasn't there before the upgrade (but I might be mistaken because I only started observing the helios64 again after the upgrade. also it seems to be related to the amount of network traffic going on. i.e. lower bitrate streams seem to not trigger the problem). Streaming via the 1GBit NIC is working fine. -
If anyone is still interested, I have a Helios 64 that I assembled, looked at, but never got around to using for more than a couple hours. Works fine, does not yet have the 2.5GB fix but I have the instructions for same. No idea what to ask for it but it certainly isn't doing me any good sitting on my shelf. Have the manual, SATA drive bay adapters for 2.5" drives and the like. Make me an offer and pay shipping from Oregon. Let's talk!
-
Hi folks, long time lurker here. My helios64 is pretty much brand new, didn’t really needed it at that time, only bought it as I found it really cool. I may power it a couple of times per year for some backups (got 3x 6tb in it, no raid so I can take them out when needed, also back up stuff to external drives), it still starts-up from the initial sd card as I never finished setting it up. I also have a 1 bay separate NAS for downloading movies that if fails, I will just replace; and a drive attached directly to my router for easy file swaps; so don’t need much running 24x7. While I work in IT (on the Windows side, so the Armbian stuff is still a learning path for me), the last years have been so busy that I can’t find myself tinkering anymore at the end of the day. To the ones of you that are running one, does it still make sense, or should I maybe switch to something more mainstream? Thank you!
-
Hello, i have trouble with my Helios64 (possibly bricked), so I am interested to by a new one. And if i can fix mine, the second one could allow me to participate to armbian support for it. Anyone have one for sale ? Preferably in Europe. Thank you.
-
A stable Armbian Bookworm configuration for your Helios64 is provided here (solved). ************************************************************************* Recently a new Armbian 23.08.1 Bookworm image with linux-6.1.50 was made available for Helios64 on its download page (see here) - which is as such great 😀. Everything starts up nicely, but unlike the previous Bookworm 23.05 image, the current one has an issue with accessing USB devices. In the boot process the following error occurs: # cat /var/log/syslog | grep error 2023-09-07T12:31:05.671598+02:00 helios64 kernel: [ 2.537009] dwc3 fe900000.usb: error -ETIMEDOUT: failed to initialize core 2023-09-07T12:31:05.671602+02:00 helios64 kernel: [ 2.537107] dwc3: probe of fe900000.usb failed with error -110 No USB device could be accessed. As this seems to be related to the realtek driver r8152, I compiled and installed the current version of that driver (see below) and after that the USB devices were accessible. # compile and install the current realtek driver git clone https://github.com/wget/realtek-r8152-linux.git cd realtek-r8152-linux... make sudo make install
-
Hi all, I am unable to login to OMV on my Helios64. A bit of sleuthing indicates that this is because the / fs is at 100% capacity. At first, I figured I'll just transfer the system install from the 8GB SD Card I started with to the 16GB internal eMMC. Turns out past unfnknblvbl already did that, and now I need to go the other way. The documentation on the old Kobol site isn't entirely accurate about how to do this. My SDCard is /dev/mmcblk1 and even though it's formatted ext4, it simply doesn't show in armbian-config. In fact, the only device that shows in the Install menu is /dev/md127, which is the RAID array itself. I'd rather not be booting from that for obvious reasons. Assuming that I'm a bit of a Linux noob (I know just enough to be dangerous), is anyone able to tell me what am I doing wrong? Thanks! 😃
-
Hello, After 5 years of loyal service, my Helios64 SBC just died on me last night. Would a Radxa Rock5 ITX+ and a M.2 to Hexa SATA Adapter could be a good drop in replacement to reuse the case? Both are Mini-ITX so it would fit. I know I would lose the front panel lights and power/reset button, and I would need to cut the back panel to fit the I/O shield but these are minor problems. What I am more concerned with, is if it is at all possible to power the 5 HDD from the radxa board (as the Helios 64 board didi). Helios engineers had made it possible to do it with minimum power, mainly by starting up the drives sequentially. Can the molex 4-Pin connector on the Radxa can do it? Provided I could buy/make an adapter to connect it to the J8 harness of the case? That would definitely be a great thing if I could reuse that very fine enclosure. Thanks for your input on that matter.

-
Hey there! I’ve been running Home Assistant Supervised on Armbian for a while, but lately I keep seeing a repeat issue after system upgrades (Docker or kernel updates). After upgrading, some HA containers stop unexpectedly, for example: odroid-c2-homeassistant:2025.12.2 exits with code 137 aarch64-addon-configurator:5.8.0 exits with code 143 My current setup runs on Helios64/RK3399 · kernel 6.12.58-current-rockchip64 · Docker CE 29.1.3 (f52814d). After digging a bit, I noticed this line in dmesg right after the failures -> apparmor="DENIED" operation="signal" profile="hassio-supervisor" signal=kill I also found the small watchdog script (supervisor_fix.sh) that restarts the Supervisor when it reports unhealthy, but the upgrade breakage seems to slip through. I’m just thinking out loud here, but maybe something like a post-upgrade AppArmor refresh, or some other small adjustment, could help ? Not sure what makes the most sense, so any input would be really appreciated. Thanks for your time and for all the work you put into Armbian!
-
Since there is a thread about adding ZFS support to the U-Boot build, I thought I'd post a similar request for btrfs. I was looking through the helios u-boot repo a few days ago and noticed that it isn't built with btrfs support. While I could make a separate ext4 /boot partition, it would be convenient to have the entire eMMC formatted as btrfs. This allows for me to make easy and fast backups using btrfs send/receive, and also allows for snapshotting prior to upgrades (via e.g. snapper), and rolling back to a different snapshot at boot. My turris onmia router uses u-boot with btrfs native root, and I've used the snapshot rollback support a couple of times. They have a fancy snapshot selection that can be done via the reset button without a serial console, but just having the ability to select previous snapshots at the u-boot menu would be quite convenient. I believe all that is needed is to enable CONFIG_CMD_BTRFS. https://github.com/u-boot/u-boot/blob/832bfad7451e2e7bd23c96edff2be050905ac3f6/cmd/Kconfig#L2047 Thanks for your consideration!
-
Trying to download new images off the Helios64 page but every link seems to lead nowhere: This armbian.lv.auroradev.org page can’t be found No webpage was found for the web address: https://armbian.lv.auroradev.org/dl/helios64/archive/Armbian_25.5.1_Helios64_bookworm_current_6.12.28_minimal.img.xz HTTP ERROR 404 Is there another place to get these?
-
Hello, I will soon be selling a working Helios64 from Kobol (with 2.5G fix done from factory). I also have 3x 6TB hard drive that could come with it if needed. Based in France, I'm able to send within EU. Please DM me if interested.
-
 Hi community, I am experiencing an issue reinstalling Armbian on my Helios64. I tried all methods including booting from an SD card, flashing the image onto the eMMC directly but every time I boot, I get kernel panic (flashing status light). I also can't connect to the USB via TTY to diagnose the issue. My macbook keeps detecting the /dev/tty.usbserial-DT03OEIM and the next second it is gone. I wanted to install the original Buster image but I cannot find it anymore in any of the archives. It's kind of disappointing because what's the purpose of an archive then if not hold on to an image for a few years. My current theories are limited and I can only think that the newer images might not have the correct drivers, but as I said, I can't connect via TTY to even observe the boot log. I tried pretty much everything at this point: all of the images available (devbian, ubuntu), all flavors of them (minimal, omv). Booting into U-boot, Setting P10, P11 jumpers etc, etc. Can anyone help?
Hi community, I am experiencing an issue reinstalling Armbian on my Helios64. I tried all methods including booting from an SD card, flashing the image onto the eMMC directly but every time I boot, I get kernel panic (flashing status light). I also can't connect to the USB via TTY to diagnose the issue. My macbook keeps detecting the /dev/tty.usbserial-DT03OEIM and the next second it is gone. I wanted to install the original Buster image but I cannot find it anymore in any of the archives. It's kind of disappointing because what's the purpose of an archive then if not hold on to an image for a few years. My current theories are limited and I can only think that the newer images might not have the correct drivers, but as I said, I can't connect via TTY to even observe the boot log. I tried pretty much everything at this point: all of the images available (devbian, ubuntu), all flavors of them (minimal, omv). Booting into U-boot, Setting P10, P11 jumpers etc, etc. Can anyone help? -
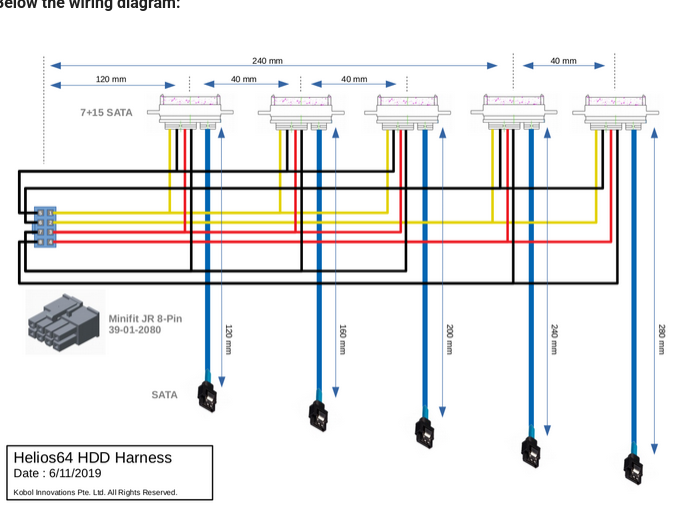
Hello, Recently the HDD Cable Harness for my Helios64 malfunctioned. SATA Ports 1 and 2 are both no longer getting power/HDDs are not spinning up. I confirmed that it was power by plugging the SATA cable into ports 3, 4, and 5 on the motherboard which all function. I also iterated through the system by removing all the HDD's and testing each HDD slot one at a time. All 5 HDDs fucntion individually in a USB drive enclosure, and all 5 function in my server system and I can mount the RAID array. My question is, does anyone know how to contact the Helios/Kobol team so I can purchase a replacement HDD Harness Cable? I checked on Aliexpress and can't find anything similar so I presume that the cable is custom. Thank you.
-
Hello, I am selling a working unit of Kobol Helios64 with the fix done, without drives. Based in Czech Republic, able to send within EU. Please DM me if interested.
-
 Hello, Armbian 25.8.1 on Helios64 BookWorm with Linux 6.12.42-current-rockchip64. I have my system booting from SD with OMV7 installed and several docker containers running. Everything is OK. Now I want to boot from emmc. Used armbian-install selecting option boot from emmc - system on emmc. Formatting and copying goes Ok, but when I reboot from emmc (extracting th SD card), OMV7 presents the web frontend, but can't log in. journalctl reports errors accessing the drives, and looking on /etc/fstab, there's only the / partition mounted. Inserting and mounting the SD card in /mnt/sdcard I can see that in /mnt/sdcard/etc/fstab there's a lot of drives ready to be mounted : eclapton@helios64:~$ cat /mnt/sdcard/etc/fstab UUID=a398270d-9378-4f2c-bedd-590b08234484 / ext4 noatime,nodiratime,defaults,commit=120,errors=remount-ro 0 1 tmpfs /tmp tmpfs defaults,nosuid 0 0 # >>> [openmediavault] /dev/disk/by-uuid/60c885fa-6af1-462c-bfa6-dc7fe706262f /srv/dev-disk-by-uuid-60c885fa-6af1-462c-bfa6-dc7fe706262f ext4 defaults,nofail,user_xattr,usrquota,grpquota,acl 0 2 /dev/disk/by-uuid/a79a14c0-3cf4-4fb9-a6c6-838571351371 /srv/dev-disk-by-uuid-a79a14c0-3cf4-4fb9-a6c6-838571351371 ext4 defaults,nofail,user_xattr,usrquota,grpquota,acl 0 2 /dev/disk/by-uuid/7b71362f-4bb4-48b6-8867-37faaedef2eb /srv/dev-disk-by-uuid-7b71362f-4bb4-48b6-8867-37faaedef2eb ext4 defaults,nofail,user_xattr,usrquota,grpquota,acl 0 2 /dev/disk/by-uuid/1f1ea692-d1bb-4539-a578-0647ef752770 /srv/dev-disk-by-uuid-1f1ea692-d1bb-4539-a578-0647ef752770 ext4 defaults,nofail,user_xattr,usrquota,grpquota,acl 0 2 /dev/disk/by-uuid/fac27973-2eba-43b4-acd3-2c3c2b10a5d7 /srv/dev-disk-by-uuid-fac27973-2eba-43b4-acd3-2c3c2b10a5d7 ext4 defaults,nofail,user_xattr,usrquota,grpquota,acl 0 2 # <<< [openmediavault] So, I thought the actual fstab was going to be copied over, unless it has to be recreated each boot by OMV. Also, I tried to copy /srv/salt and /srv/pillar from the old system on the SD card to the new one on the emmc, as instructed un Kobol's webpage, and it helps making openmediavault-issue start, but the webpage doesn't still work. sudo systemctl status shows nginx is not able to start : eclapton@helios64:~$ sudo systemctl status nginx × nginx.service - A high performance web server and a reverse proxy server Loaded: loaded (/lib/systemd/system/nginx.service; enabled; preset: enabled) Active: failed (Result: exit-code) since Mon 2025-09-22 23:07:25 CEST; 57s ago Docs: man:nginx(8) Process: 40902 ExecStartPre=/usr/sbin/nginx -t -q -g daemon on; master_process on; (code=exited, status=1/FAILURE) CPU: 82ms sep 22 23:07:25 helios64 systemd[1]: Starting nginx.service - A high performance web server and a reverse proxy server... sep 22 23:07:25 helios64 nginx[40902]: 2025/09/22 23:07:25 [emerg] 40902#40902: open() "/var/log/nginx/error.log" failed (2: No such file or > sep 22 23:07:25 helios64 nginx[40902]: nginx: configuration file /etc/nginx/nginx.conf test failed sep 22 23:07:25 helios64 systemd[1]: nginx.service: Control process exited, code=exited, status=1/FAILURE sep 22 23:07:25 helios64 systemd[1]: nginx.service: Failed with result 'exit-code'. sep 22 23:07:25 helios64 systemd[1]: Failed to start nginx.service - A high performance web server and a reverse proxy server. I suspect there's somewhere I have to change /dev/mmcblk1p1 for /dev/mmcblk0p1... but where? What am I missing? Thanks for your help.
Hello, Armbian 25.8.1 on Helios64 BookWorm with Linux 6.12.42-current-rockchip64. I have my system booting from SD with OMV7 installed and several docker containers running. Everything is OK. Now I want to boot from emmc. Used armbian-install selecting option boot from emmc - system on emmc. Formatting and copying goes Ok, but when I reboot from emmc (extracting th SD card), OMV7 presents the web frontend, but can't log in. journalctl reports errors accessing the drives, and looking on /etc/fstab, there's only the / partition mounted. Inserting and mounting the SD card in /mnt/sdcard I can see that in /mnt/sdcard/etc/fstab there's a lot of drives ready to be mounted : eclapton@helios64:~$ cat /mnt/sdcard/etc/fstab UUID=a398270d-9378-4f2c-bedd-590b08234484 / ext4 noatime,nodiratime,defaults,commit=120,errors=remount-ro 0 1 tmpfs /tmp tmpfs defaults,nosuid 0 0 # >>> [openmediavault] /dev/disk/by-uuid/60c885fa-6af1-462c-bfa6-dc7fe706262f /srv/dev-disk-by-uuid-60c885fa-6af1-462c-bfa6-dc7fe706262f ext4 defaults,nofail,user_xattr,usrquota,grpquota,acl 0 2 /dev/disk/by-uuid/a79a14c0-3cf4-4fb9-a6c6-838571351371 /srv/dev-disk-by-uuid-a79a14c0-3cf4-4fb9-a6c6-838571351371 ext4 defaults,nofail,user_xattr,usrquota,grpquota,acl 0 2 /dev/disk/by-uuid/7b71362f-4bb4-48b6-8867-37faaedef2eb /srv/dev-disk-by-uuid-7b71362f-4bb4-48b6-8867-37faaedef2eb ext4 defaults,nofail,user_xattr,usrquota,grpquota,acl 0 2 /dev/disk/by-uuid/1f1ea692-d1bb-4539-a578-0647ef752770 /srv/dev-disk-by-uuid-1f1ea692-d1bb-4539-a578-0647ef752770 ext4 defaults,nofail,user_xattr,usrquota,grpquota,acl 0 2 /dev/disk/by-uuid/fac27973-2eba-43b4-acd3-2c3c2b10a5d7 /srv/dev-disk-by-uuid-fac27973-2eba-43b4-acd3-2c3c2b10a5d7 ext4 defaults,nofail,user_xattr,usrquota,grpquota,acl 0 2 # <<< [openmediavault] So, I thought the actual fstab was going to be copied over, unless it has to be recreated each boot by OMV. Also, I tried to copy /srv/salt and /srv/pillar from the old system on the SD card to the new one on the emmc, as instructed un Kobol's webpage, and it helps making openmediavault-issue start, but the webpage doesn't still work. sudo systemctl status shows nginx is not able to start : eclapton@helios64:~$ sudo systemctl status nginx × nginx.service - A high performance web server and a reverse proxy server Loaded: loaded (/lib/systemd/system/nginx.service; enabled; preset: enabled) Active: failed (Result: exit-code) since Mon 2025-09-22 23:07:25 CEST; 57s ago Docs: man:nginx(8) Process: 40902 ExecStartPre=/usr/sbin/nginx -t -q -g daemon on; master_process on; (code=exited, status=1/FAILURE) CPU: 82ms sep 22 23:07:25 helios64 systemd[1]: Starting nginx.service - A high performance web server and a reverse proxy server... sep 22 23:07:25 helios64 nginx[40902]: 2025/09/22 23:07:25 [emerg] 40902#40902: open() "/var/log/nginx/error.log" failed (2: No such file or > sep 22 23:07:25 helios64 nginx[40902]: nginx: configuration file /etc/nginx/nginx.conf test failed sep 22 23:07:25 helios64 systemd[1]: nginx.service: Control process exited, code=exited, status=1/FAILURE sep 22 23:07:25 helios64 systemd[1]: nginx.service: Failed with result 'exit-code'. sep 22 23:07:25 helios64 systemd[1]: Failed to start nginx.service - A high performance web server and a reverse proxy server. I suspect there's somewhere I have to change /dev/mmcblk1p1 for /dev/mmcblk0p1... but where? What am I missing? Thanks for your help. -
 Hello everyone, I'm experiencing frequent network disconnections on my system running Armbian 24.5.3, both with Bookworm and Noble bases, which are both using Kernel 6.6.39. This issue becomes particularly frustrating when syncing files with Unison, as the interruptions disrupt the process frequently. To provide some background, I didn't encounter these network issues when I was using the last Focal version, which was running on Kernel 5.x. The current versions of Samba I'm using are 4.17.12-Debian on Bookworm and 4.19.5-Ubuntu on Noble. Unison is at version 2.52.1 on Bookworm and 2.53.3 on Noble. Both systems also have the latest updates for MDADM and OpenSSH from the standard package repositories. In the logs (journalctl -xe), I've noticed the following messages repeatedly: kernel: r8152 2-1.4:1.0 enx646266d00567: Tx timeout kernel: r8152 2-1.4:1.0 enx646266d00567: Tx status -2 These errors are accompanied by the following, occurring approximately 15 seconds earlier: kernel: xhci-hcd xhci-hcd.0.auto: WARN Event TRB for slot 3 ep 3 with no TDs queued? kernel: xhci-hcd xhci-hcd.0.auto: WARN Event TRB for slot 3 ep 3 with no TDs queued? kernel: xhci-hcd xhci-hcd.0.auto: WARN Event TRB for slot 3 ep 3 with no TDs queued? kernel: xhci-hcd xhci-hcd.0.auto: ERROR Transfer event TRB DMA ptr not part of current TD ep_index 3 comp_code 1 kernel: xhci-hcd xhci-hcd.0.auto: Looking for event-dma 000000000908e050 trb-start 000000000908e020 trb-end 000000000908e020 seg-start 000000000908e000 seg-end 000000000908eff0 kernel: xhci-hcd xhci-hcd.0.auto: ERROR Transfer event TRB DMA ptr not part of current TD ep_index 3 comp_code 1 kernel: xhci-hcd xhci-hcd.0.auto: Looking for event-dma 000000000908e060 trb-start 000000000908e020 trb-end 000000000908e020 seg-start 000000000908e000 seg-end 000000000908eff0 kernel: xhci-hcd xhci-hcd.0.auto: ERROR Transfer event TRB DMA ptr not part of current TD ep_index 3 comp_code 1 kernel: xhci-hcd xhci-hcd.0.auto: Looking for event-dma 000000000908e070 trb-start 000000000908e020 trb-end 000000000908e020 seg-start 000000000908e000 seg-end 000000000908eff0 kernel: xhci-hcd xhci-hcd.0.auto: ERROR Transfer event TRB DMA ptr not part of current TD ep_index 3 comp_code 1 kernel: xhci-hcd xhci-hcd.0.auto: Looking for event-dma 000000000908e080 trb-start 000000000908e020 trb-end 000000000908e020 seg-start 000000000908e000 seg-end 000000000908eff0 kernel: xhci-hcd xhci-hcd.0.auto: ERROR Transfer event TRB DMA ptr not part of current TD ep_index 3 comp_code 1 kernel: xhci-hcd xhci-hcd.0.auto: Looking for event-dma 000000000908e090 trb-start 000000000908e020 trb-end 000000000908e020 seg-start 000000000908e000 seg-end 000000000908eff0 kernel: xhci-hcd xhci-hcd.0.auto: ERROR Transfer event TRB DMA ptr not part of current TD ep_index 3 comp_code 1 kernel: xhci-hcd xhci-hcd.0.auto: Looking for event-dma 000000000908e0a0 trb-start 000000000908e020 trb-end 000000000908e020 seg-start 000000000908e000 seg-end 000000000908eff0 kernel: xhci-hcd xhci-hcd.0.auto: ERROR Transfer event TRB DMA ptr not part of current TD ep_index 3 comp_code 1 kernel: xhci-hcd xhci-hcd.0.auto: Looking for event-dma 000000000908e0b0 trb-start 000000000908e020 trb-end 000000000908e020 seg-start 000000000908e000 seg-end 000000000908eff0 kernel: xhci-hcd xhci-hcd.0.auto: ERROR Transfer event TRB DMA ptr not part of current TD ep_index 3 comp_code 1 kernel: xhci-hcd xhci-hcd.0.auto: Looking for event-dma 000000000908e0c0 trb-start 000000000908e020 trb-end 000000000908e020 seg-start 000000000908e000 seg-end 000000000908eff0 kernel: xhci-hcd xhci-hcd.0.auto: ERROR Transfer event TRB DMA ptr not part of current TD ep_index 3 comp_code 1 kernel: xhci-hcd xhci-hcd.0.auto: Looking for event-dma 000000000908e110 trb-start 000000000908e020 trb-end 000000000908e020 seg-start 000000000908e000 seg-end 000000000908eff0 kernel: xhci-hcd xhci-hcd.0.auto: ERROR Transfer event TRB DMA ptr not part of current TD ep_index 3 comp_code 1 kernel: xhci-hcd xhci-hcd.0.auto: Looking for event-dma 000000000908e120 trb-start 000000000908e020 trb-end 000000000908e020 seg-start 000000000908e000 seg-end 000000000908eff0 I've come across advice suggesting the installation of the correct driver, but that hasn't been very helpful so far. Has anyone else faced similar issues with network stability, particularly under heavy load (e.g., large file transfers)? If so, what steps did you take to resolve it? I would greatly appreciate any insights or recommendations on how to diagnose or fix this problem. Thank you in advance for your assistance! Best regards, mtlmarko189 edit: Please forgive if I should have overlooked the same topic, but unfortunately I have not found what I was looking for on the topic regarding Helios64.
Hello everyone, I'm experiencing frequent network disconnections on my system running Armbian 24.5.3, both with Bookworm and Noble bases, which are both using Kernel 6.6.39. This issue becomes particularly frustrating when syncing files with Unison, as the interruptions disrupt the process frequently. To provide some background, I didn't encounter these network issues when I was using the last Focal version, which was running on Kernel 5.x. The current versions of Samba I'm using are 4.17.12-Debian on Bookworm and 4.19.5-Ubuntu on Noble. Unison is at version 2.52.1 on Bookworm and 2.53.3 on Noble. Both systems also have the latest updates for MDADM and OpenSSH from the standard package repositories. In the logs (journalctl -xe), I've noticed the following messages repeatedly: kernel: r8152 2-1.4:1.0 enx646266d00567: Tx timeout kernel: r8152 2-1.4:1.0 enx646266d00567: Tx status -2 These errors are accompanied by the following, occurring approximately 15 seconds earlier: kernel: xhci-hcd xhci-hcd.0.auto: WARN Event TRB for slot 3 ep 3 with no TDs queued? kernel: xhci-hcd xhci-hcd.0.auto: WARN Event TRB for slot 3 ep 3 with no TDs queued? kernel: xhci-hcd xhci-hcd.0.auto: WARN Event TRB for slot 3 ep 3 with no TDs queued? kernel: xhci-hcd xhci-hcd.0.auto: ERROR Transfer event TRB DMA ptr not part of current TD ep_index 3 comp_code 1 kernel: xhci-hcd xhci-hcd.0.auto: Looking for event-dma 000000000908e050 trb-start 000000000908e020 trb-end 000000000908e020 seg-start 000000000908e000 seg-end 000000000908eff0 kernel: xhci-hcd xhci-hcd.0.auto: ERROR Transfer event TRB DMA ptr not part of current TD ep_index 3 comp_code 1 kernel: xhci-hcd xhci-hcd.0.auto: Looking for event-dma 000000000908e060 trb-start 000000000908e020 trb-end 000000000908e020 seg-start 000000000908e000 seg-end 000000000908eff0 kernel: xhci-hcd xhci-hcd.0.auto: ERROR Transfer event TRB DMA ptr not part of current TD ep_index 3 comp_code 1 kernel: xhci-hcd xhci-hcd.0.auto: Looking for event-dma 000000000908e070 trb-start 000000000908e020 trb-end 000000000908e020 seg-start 000000000908e000 seg-end 000000000908eff0 kernel: xhci-hcd xhci-hcd.0.auto: ERROR Transfer event TRB DMA ptr not part of current TD ep_index 3 comp_code 1 kernel: xhci-hcd xhci-hcd.0.auto: Looking for event-dma 000000000908e080 trb-start 000000000908e020 trb-end 000000000908e020 seg-start 000000000908e000 seg-end 000000000908eff0 kernel: xhci-hcd xhci-hcd.0.auto: ERROR Transfer event TRB DMA ptr not part of current TD ep_index 3 comp_code 1 kernel: xhci-hcd xhci-hcd.0.auto: Looking for event-dma 000000000908e090 trb-start 000000000908e020 trb-end 000000000908e020 seg-start 000000000908e000 seg-end 000000000908eff0 kernel: xhci-hcd xhci-hcd.0.auto: ERROR Transfer event TRB DMA ptr not part of current TD ep_index 3 comp_code 1 kernel: xhci-hcd xhci-hcd.0.auto: Looking for event-dma 000000000908e0a0 trb-start 000000000908e020 trb-end 000000000908e020 seg-start 000000000908e000 seg-end 000000000908eff0 kernel: xhci-hcd xhci-hcd.0.auto: ERROR Transfer event TRB DMA ptr not part of current TD ep_index 3 comp_code 1 kernel: xhci-hcd xhci-hcd.0.auto: Looking for event-dma 000000000908e0b0 trb-start 000000000908e020 trb-end 000000000908e020 seg-start 000000000908e000 seg-end 000000000908eff0 kernel: xhci-hcd xhci-hcd.0.auto: ERROR Transfer event TRB DMA ptr not part of current TD ep_index 3 comp_code 1 kernel: xhci-hcd xhci-hcd.0.auto: Looking for event-dma 000000000908e0c0 trb-start 000000000908e020 trb-end 000000000908e020 seg-start 000000000908e000 seg-end 000000000908eff0 kernel: xhci-hcd xhci-hcd.0.auto: ERROR Transfer event TRB DMA ptr not part of current TD ep_index 3 comp_code 1 kernel: xhci-hcd xhci-hcd.0.auto: Looking for event-dma 000000000908e110 trb-start 000000000908e020 trb-end 000000000908e020 seg-start 000000000908e000 seg-end 000000000908eff0 kernel: xhci-hcd xhci-hcd.0.auto: ERROR Transfer event TRB DMA ptr not part of current TD ep_index 3 comp_code 1 kernel: xhci-hcd xhci-hcd.0.auto: Looking for event-dma 000000000908e120 trb-start 000000000908e020 trb-end 000000000908e020 seg-start 000000000908e000 seg-end 000000000908eff0 I've come across advice suggesting the installation of the correct driver, but that hasn't been very helpful so far. Has anyone else faced similar issues with network stability, particularly under heavy load (e.g., large file transfers)? If so, what steps did you take to resolve it? I would greatly appreciate any insights or recommendations on how to diagnose or fix this problem. Thank you in advance for your assistance! Best regards, mtlmarko189 edit: Please forgive if I should have overlooked the same topic, but unfortunately I have not found what I was looking for on the topic regarding Helios64.


