

AxelFoley
-
Posts
69 -
Joined
-
Last visited
Content Type
Forums
Store
Crowdfunding
Applications
Events
Raffles
Community Map
Posts posted by AxelFoley
-
-
Nah I think the above hypothesis is wrong, in some respects.
My (poor) understanding of the boot process is;
1). First/Primary Boot Stage loader is BROM in the SOC's Chip initiated to enable enough HW to find the main boot loader (e.g. U-boot's SPL Secondary Boot Loader which is loaded on SPIFlash/eMMC/SDMMC Card),
2). The U-Boots SPL then initiates more HW (such as DDR Memory) to enable the full U-Boot to be loaded into larger memory space.
>> I suspect that this is a legacy constraint ... legacy systems had limited memory so any boot loader needs to fit into those smaller memory environments for backwards compatibility.
>> however if it can probe and detect more memory (NAND,NOR Flash Chips, eMMC, SDMMC & DDR Memory). This is Where the TPL Comes in
3). Tertiary Program Loader (to look for larger memory HW in which the SPI can load a bigger version of U-Boot out side of legacy constrained HW).
>> So I think that both eMMC's U-Boot SPL Part of the boot image is being initialised on the eMMC (nee MMC lines in the serial output as eMMC is treated as SDMMC). It immediately loads the TPL to initialise the DDR memory and this explains why you see the TPL before the SPL in the output. The reason why the working Auyfan's has more verbose DDR output is because he is using a debug version of U-Boot;
Auyfan working u-boot ( v1.3(debug):370ab80) SPL finds kernel image on eMMC Found /boot/extlinux/extlinux.conf ...Retrieving file: /boot/vmlinuz-4.4.190-1233-rockchip-ayufan-gd3f1be0ed310
Armbian non working u-boot v1.3(release):845ee93 SPL finds kernel image on eMMC Found U-Boot script /boot/boot.scr
so TPL hands back to SPL again after initialising the DDR Memory so SPL can load the big U-Boot image into DDR Memory .... but this is where I think the problem is ....
Both images seem to try to load a Ram Disk to load the kernel into
Aufan; ## Flattened Device Tree blob at 01f00000
Booting using the fdt blob at 0x1f00000
Loading Ramdisk to f5902000, end f5f00ca8 ... OK
Loading Device Tree to 00000000f58e7000, end 00000000f5901810 ... OKArmbian; Applying kernel provided DT fixup script (rockchip-fixup.scr)
## Executing script at 09000000
Moving Image from 0x2080000 to 0x2200000, end=3f90000
## Loading init Ramdisk from Legacy Image at 06000000 ...
Image Name: uInitrd
Image Type: AArch64 Linux RAMDisk Image (gzip compressed)
Data Size: 14238821 Bytes = 13.6 MiB
Load Address: 00000000
Entry Point: 00000000
Verifying Checksum ... OK
## Flattened Device Tree blob at 01f00000
Booting using the fdt blob at 0x1f00000So I need to look at what this "rockchip-fixup.scr" is actually doing that Auyan's image is not. because it looks to me like the Armbian image is failing to load the kernel into DDR memory.
Now this may be down to this line in the Armbian Boot process;
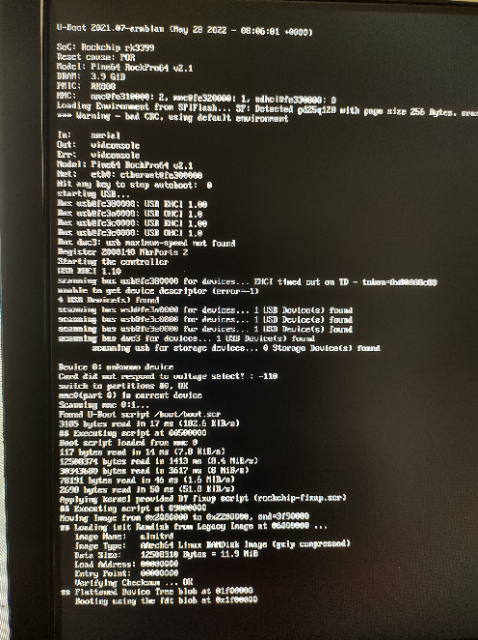
Device 0: unknown device
Card did not respond to voltage select! : -110
switch to partitions #0, OK>> I wonder if its the NVMe storage that's confusing the Armbian image boot process and preventing it from loading the kernel into DDR.
Time for bed but tomorrow I'll disconnect the PCIe NVMe device and see if Armbian boots !
-
Well after a bit of tracing the serial output of the boot load process and looking at a working ayufan image against a Armbian Image (5 kernel) it looks like they have a different way of implementing U-Boot for the RockPro64 RK3399.
Note my test boards come with PCIe NVMe Drives and the board provides 128Mb SPI boot Flash and 64GbE eMMC Storage from which I am trying to boot the kernel.
Not booting eMMC: Armbian TPL -> SPL-> U-Boot -> Kernel
Booting eMMC: Ayufan SPL -> U-Boot -> kernel
>> What I notice is that Ayufan image has a serial boot output prefixed by what looks like a LDDR Memory test/probe.
The boot sequence should be consistent at first then deviate, not deviate right from the start !
RTFM Here https://wiki.pine64.org/wiki/RK3399_boot_sequence
"It employs 5 strategies, in order, to load a bootloader from off-chip:
loading from NOR flash on SPI1
loading from NAND flash on SPI1
loading from eMMC
loading from SD on the SDMMC controller
bringing up the OTG0 USB controller in device mode and accepting control transfers to load programs
Loading a bootloader from storage is done in 4 steps:
Probing the boot device
Finding the ID block
Loading the first stage of the bootloader to main SRAM and running it
(if the first stage returned to BROM) Loading the second stage to low DRAM and running it"
>> I have a suspicion that Ayufan's images have loaded a U-Boot Boot loader into SPI Flash and, perhaps that may be the issue as to why his images work but others do not.
His kernel may be located at address below in eMMC but other boot images are not.
"Booting using the fdt blob at 0x1f00000"
I'll see if I can wipe the SPI Flash and see if Armbian starts to boot.
-
-
1 hour ago, TheLinuxBug said:
Can you actually attach a USB TTL serial adapter and look to see if there are any specific errors with the EMMC being loaded? Usually this type of issue indicates a change in u-boot, not the image it's self. It would seem like maybe a change to the dtb was made that has somehow disabled the emmc.
With a little research you can probably pull the u-boot off of an older image and stick it on a new one to test or you can use an older image and upgrade it. Lastly you could manually build u-boot your self and add it to the new image.
And yes, a lot of these things are a moving target since there are a lot of boards in Rockchip64 and it appears as updates are made for the family, some of the fixes break other things. I know the developers have been fighting with some of this.
In general though, as long as the emmc is enabled in dtb there should be no reason you can't write to and boot from the emmc.
my 2 cents.
Cheers!
>> Thx Serial console cable on order lets see what I can see tomorrow.
-
Tried setting extraargs="mmc_cmdqueue=off" Still same error.
When I googled around a bit, one suggestion was that it was caused by the 1st n byte's of the eMMC chip getting nulled out deleting the normal boot partition location and that the solution was to move the boot sector to a new address range outside that first n bytes... but I'm no boot expert ... I'll do some digging;
-
Hi @Igor,
I am happy to contribute to the project if it helps.
Do the maintainers need a Pine RockPro64 with 64Gb eMMC ?
I can order a couple more at the end of the month and send one to the maintainers. just let me know with a DM.
I'm also happy to test releases if people want me to, but I spend most of my free time on DE10 Nano and the Pine RocPro64 Pico Clusters I run are mainly to test orchestration toolsets like Ansible and SaltStack and Distributed DB's like Cassandra.
I have a VMWare Server to run RHEL Container platforms like Openshift to test things like Service Discovery Consul and Monitoring with Prometheus/Grafana for proprietary apps.
That's my background I'm no bootstrap expert (after UEFI I gave up interest in the subject), but I can pick stuff up
I don't check this forum often so somebody would have to reach out to me to be part of a QA Process for that board.
I seem to spend weeks when I am doing a cluster rebuild just testing and trying to find a stable image that is;
1). Debian based distro
2). 64bit (arm64)
3). That boots to eMMC.
4). That has a Desktop build for the control plane node that supports attached Nvme Storage
5). That has a CLI build for the worker nodes.
Its seems to be a constant problem with these Pine RockPro64 boards.
They are hardly an AliExpress Clone outfit ... Pine are quite well established 🙂 www.pine64.org
Let me know how you feel I can contribute
-
This was my goto distro and Im going to have to find another one because of the lack of support for eMMC going forward.
Why has the 5 kernels led to the drop in support for eMMC?
-
https://wiki.pine64.org/wiki/ROCKPro64_Software_Release
"If you are booting from a Micro SD card, then both Linux kernel versions will work. If you are trying to boot from an eMMC module then the 4.4.y will work, but the newer 5.10.y will not."
Doh ! So you will need to flash to 4.4.y or boot from SD Card if you want Armbian
-
Happens on both the CLI and GUI Desktop Images tried flashing in Rufus and Etcher
It simply dose not work on eMMC .... so I don't know how this could get released without the basics being checked.
I'm not going to buy SD Cards for my 20 node clusters !
-
No you are not the only person. The Image is screwed and wont boot when flashed to eMMC. It boots from SD.
I'm looking into the problem now.
-
I have been monitoring the voltage and current draw of an individual RockPro64 on boot with the PCIe NVME Connected going to console.
I then launched the desktop as both root (Armbian desktop) and pico user (looks like XFCE) and looked for any power spikes.
There was none!
Both tests caused a lockup and HW Freeze.
On boot the peak current draw was 0.7A with 12v steady, and current draw dropping to 0.3A steady.
Then I launched Xorg as root (in the past tended to be more stable) and user pico (always locked up immediately)
I did notice a difference when I ran startx as pico user and it launched XFCE .. its current draw peaked at 0.7a and voltage dropped to 11.96V
Desktop immediately locked the board on launch.
When I ran startx as root and it launched armbian desktop ... it only peaked at 0.6A and voltage never dipped below 12v.
The desktop was responsive until when I loaded the Armbian forum in chrome and triggered the board lockup ..... there was no current spike or voltage drop! The board locked up while only drawing 0.29A.
I checked the Pine forum and other people are reporting exactly the same issue as myself with the PCIe/NVMe setup.
One person in 2018 reported he fixed the issue by launching a different kernel.
I have logged the problem on the pine forum and got this response;
"Currently working on the issue. It seems - as odd is its sounds - that the problem is somehow linked to pulseaudio. If you uninstall pulseaudio, and use alsa instead, the issue will just vanish. We have tried blacklisting PCIe for pulse in udev, and it prevents the issue from happening, but it also returns a segmentation error (SATA card / other adapter not accessible). Its very very strange".
Should I stop posting here and move the discussion to Pine ?



-
@TonyMac32 Thankfully I have the RockPro64 v2.1 board.
-
@pfry
Looking at the power Specifications for PCIe x 4 => Suggest that it can be powered from 3.3v (9.9W) & 12v (25W), however from the RockPro64 Power schema it looks like they negate to feed the 12v rail from the Supply voltage to the PCIe.
Instead Pine feeds the PCIe Interface on the board only by the 3.3v (3A) rail (9.9W).
From the Power schema It also looks like the board designers feed PCIe from the 5.1v rail converted by the RK808 PMU to 1.8v on vcc1v8_pcie (not sure how this is intended to be used on PCIe)
I am using the Pine PCIe ver 3.0 NVMe Card with a Samsung 970 EVO 500GB and a RockPro64 v2.1 Board. PSU is a 102W 12v LRS-100-12
The Max power draw of the EVO 970 NVMe is 5.8W (1.76A) which should be within spec for that 3.3v rail.
But this bit worry's me "vcc_sys: could not add device link regulator.6 err -2"
vcc_sys is the 3.3v rail that feeds the vcc3v3_pcie feed into the PCIe Socket.
Although dmeag later says it can enable a regulator for the 3.3v vcc3v3_pcie rail hanging off vcc3v3_sys.
I also see this warning;
"Apr 8 19:09:24 localhost kernel: [ 2.010352] pci_bus 0000:01: busn_res: can not insert [bus 01-ff] under [bus 00-1f] (conflicts with (null) [bus 00-1f])"I may have to get out a JTAG debugger to work this one out :-(
Not sure if this is a kernel driver issue or HW Power design.
ill see if I can get any Gerber files to scope out the voltage and current spikes.
-
I think I have found the issue !!!!!!!
Its the PCIe Express NVMe Card.
I remove it and the desktop seems not to hang .... I add it back in .... and the desktop hangs.
I wonder if this has something to do with power spikes when there is graphics activity the errors in the dmesg indicate that
vpcie1v8 = 5.1v rail Shared with GPU
vpcie0v9 = 3v Rail
Both of these rails hang off the same core buck converter SY8113B, the other SY8113B manages the USB peripherals seperatly.
@AndrewDB .... looks like you may be correct it was power all along but it looks like its a kernel issue with the PCIe Power Management ?
-
Interesting!!!! Fresh build on the spare EMMC64 Armbian_5.75_Rockpro64_Ubuntu_bionic_default_4.4.174_desktop.img
created new user pico after changing the root password.
The Device initiated nodm which initiated Xorg. Loaded the Armbian desktop ....... and hung immediately! HW Freeze and lock screen.
Subsequent boots only boot to command-line with login prompt not desktop. /etc/default/nodem still has user root as default user to log in not pico.
manually starting startx results in black screen of death as pico user (or on second try HW lockup see attached) but root user loads desktop OK when running startx
I have done no apt upgrade && apt update
armbianmonitor -u results below.
mmc driver issues
[Mon Apr 8 19:23:29 2019] rockchip_mmc_get_phase: invalid clk rate
[Mon Apr 8 19:23:29 2019] rockchip_mmc_get_phase: invalid clk rate
[Mon Apr 8 19:23:29 2019] rockchip_mmc_get_phase: invalid clk rate
[Mon Apr 8 19:23:29 2019] rockchip_mmc_get_phase: invalid clk ratePMU issues may affect efficiency of CPU idle when not under load
[Mon Apr 8 19:23:29 2019] rockchip_clk_register_frac_branch: could not find dclk_vop0_frac as parent of dclk_vop0, rate changes may not work
[Mon Apr 8 19:23:29 2019] rockchip_clk_register_frac_branch: could not find dclk_vop1_frac as parent of dclk_vop1, rate changes may not worksome possible pcie\nvme issues
[Mon Apr 8 19:23:30 2019] rockchip-pcie f8000000.pcie: Looking up vpcie1v8-supply property in node /pcie@f8000000 failed
[Mon Apr 8 19:23:30 2019] rockchip-pcie f8000000.pcie: no vpcie1v8 regulator found
[Mon Apr 8 19:23:30 2019] rockchip-pcie f8000000.pcie: Looking up vpcie0v9-supply from device tree
[Mon Apr 8 19:23:30 2019] rockchip-pcie f8000000.pcie: Looking up vpcie0v9-supply property in node /pcie@f8000000 failed[Mon Apr 8 19:23:31 2019] pci 0000:00:00.0: bridge configuration invalid ([bus 00-00]), reconfiguring
[Mon Apr 8 19:23:31 2019] pci_bus 0000:01: busn_res: can not insert [bus 01-ff] under [bus 00-1f] (conflicts with (null) [bus 00-1f])some pwm issues
[Mon Apr 8 19:23:31 2019] pwm-regulator: supplied by vcc_sys
[Mon Apr 8 19:23:31 2019] vcc_sys: could not add device link regulator.8 err -2
[Mon Apr 8 19:23:31 2019] vcc_sys: could not add device link regulator.8 err -2[Mon Apr 8 19:23:31 2019] vcc_sys: could not add device link regulator.11 err -2
.... etc a load of these
some sound driver issues
[Mon Apr 8 19:23:32 2019] of_get_named_gpiod_flags: can't parse 'simple-audio-card,hp-det-gpio' property of node '/spdif-sound[0]'
[Mon Apr 8 19:23:32 2019] of_get_named_gpiod_flags: can't parse 'simple-audio-card,mic-det-gpio' property of node '/spdif-sound[0]'
[Mon Apr 8 19:23:32 2019] rockchip-spdif ff870000.spdif: Missing dma channel for stream: 0
[Mon Apr 8 19:23:32 2019] rockchip-spdif ff870000.spdif: ASoC: pcm constructor failed: -22
[Mon Apr 8 19:23:32 2019] asoc-simple-card spdif-sound: ASoC: can't create pcm ff870000.spdif-dit-hifi :-22
[Mon Apr 8 19:23:32 2019] asoc-simple-card spdif-sound: ASoC: failed to instantiate card -22some Ethernet nic issues (but still works)
[Mon Apr 8 19:23:46 2019] cdn-dp fec00000.dp: Direct firmware load for rockchip/dptx.bin failed with error -2
[Mon Apr 8 19:24:02 2019] cdn-dp fec00000.dp: Direct firmware load for rockchip/dptx.bin failed with error -2
[Mon Apr 8 19:24:35 2019] cdn-dp fec00000.dp: Direct firmware load for rockchip/dptx.bin failed with error -2
[Mon Apr 8 19:25:39 2019] cdn-dp fec00000.dp: [drm:cdn_dp_request_firmware] *ERROR* Timed out trying to load firmware[Mon Apr 8 19:23:32 2019] asoc-simple-card: probe of spdif-sound failed with error -22
-
1 hour ago, balbes150 said:
For what purpose do you need a cluster ?
@balbes150 It for prototyping, education and engineering ... essentially enabling a quick and dirty evaluation of SOA (Service Oriented Architecture) concepts for myself and some other devs. e.g. NOSQL Databases and in particular how to integrate Service discovery and RDMA paradigm's such as the OFED stack (RoCE), and building restFul interfaces & API Abstraction while understanding principles such as standardized Data and message models. In essence to evangelize open source software and frameworks as a solution to proprietary software integration & inter-operation inertia.
-
4 hours ago, AndrewDB said:
This is all you need to know, actually. As I wrote before, this is a problem with hardware acceleration being used by Chromium. You can turn it off in advanced settings.
@AndrewDB apologies I missed the suggestion ... I disabled the HW Acceleration and restarted chrome from the terminal. Disabling the HW Acceleration stopped error messages being displayed in stdout.
However the rockpro64 still locked up with a HW freeze loading the Armbian forum. But I think the whole graphics drivers on some of my cluster node have gone foo-bar for some reason.
I may need to "apt install --reinstall [graphics subsystem packages] " to be sure that this is a bug not a missing library during interrupted apt update && apt upgrade
-
Right I have now caught up with everybody's comments and questions and hopefully answered them.
I now need some guidance on what to do next ....
### Hypothesis 1 ###:
The root cause of the instability was a fundamental issue with the current Armbian code base (kernel/driver) and the rockpro64 4GB V2.1 + NVME + 64GB EMMC triggered by chromium loading the Armbian forum (100% reproducible)
*** Action ***
Continue to troubleshoot the unstable cluster master when using Chromium and figure out how to trap the HW Lockup when chromium launches the Armbian forum (nothing captured in the system log files
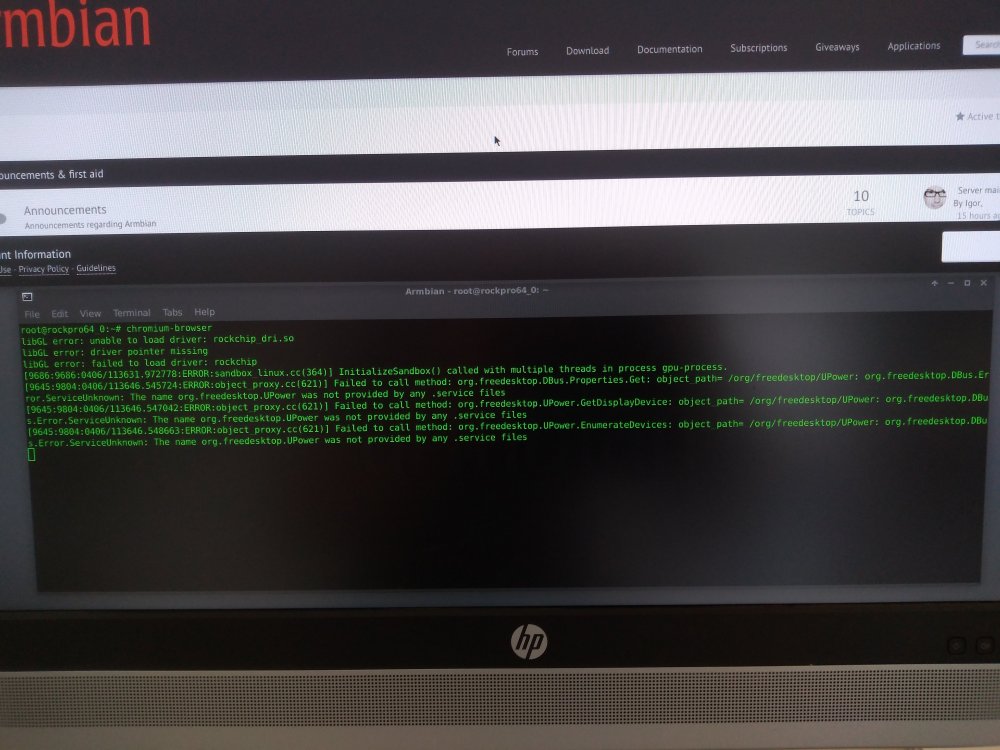
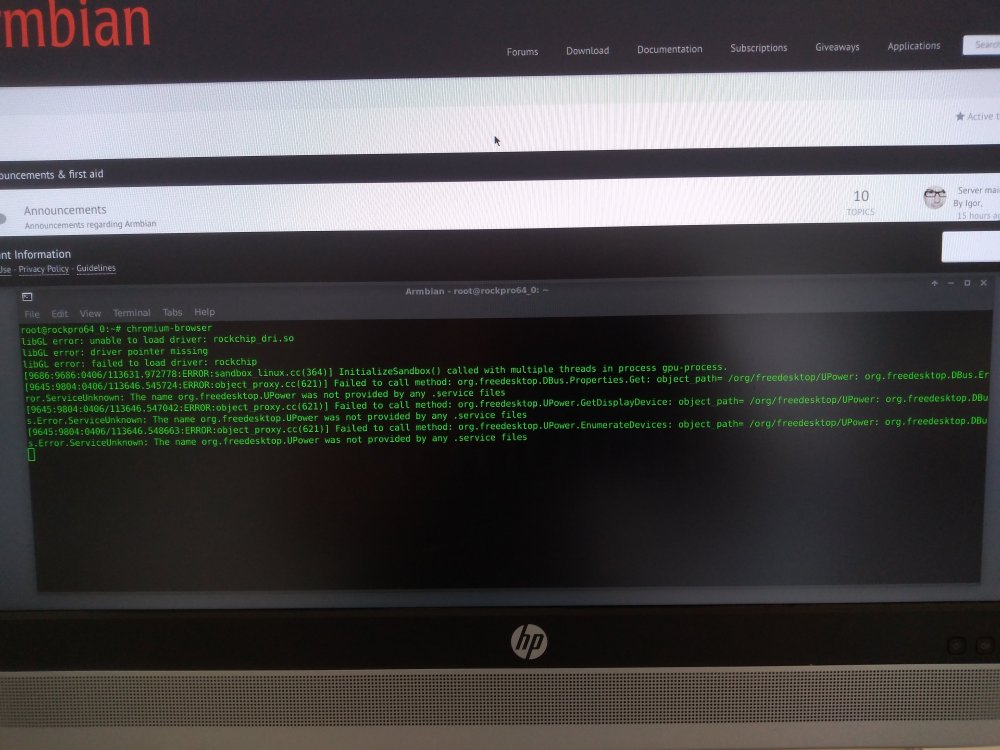
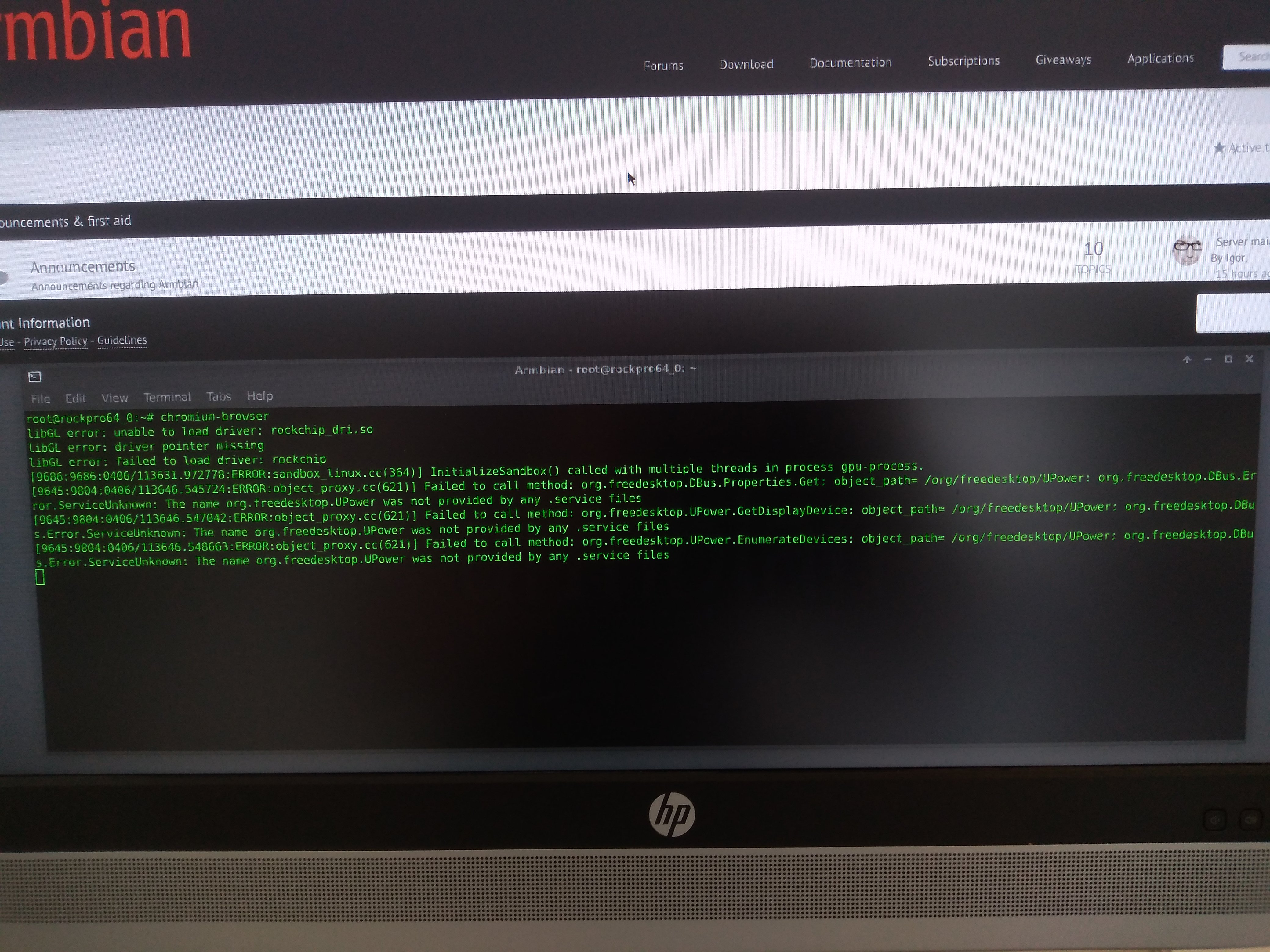
The only hint I get is from launching Chromium from a terminal (thanks @NicoD I had no leads until you suggested this as it was a complete HW Freeze\Lockup);
root@rockpro64_0:~# chromium-browser
libGL error: unable to load driver: rockchip_dri.so
libGL error: driver pointer missing
libGL error: failed to load driver: rockchip
[17517:17517:0406/144119.625593:ERROR:sandbox_linux.cc(364)] InitializeSandbox() called with multiple threads in process gpu-process.
[17647:17672:0406/144121.185188:ERROR:command_buffer_proxy_impl.cc(124)] ContextResult::kTransientFailure: Failed to send GpuChannelMsg_CreateCommandBuffer.### Hypothesis 2###:
The root cause of the issue is a corrupted Ambian installation caused by interruption to salt distributed "apt-get update && apt-get upgrade" (indicated by the need to force reinstall libegli due to missing libraries)
*** Action ***
Reformat the entire cluster using a desktop edition for the master and a cli version for the nodes and retest to see if we can recreate the issues with Chromium and also see if 20% of the nodes are still rebooting constantly.
I have a spare EMMC 64 Chip so I can save the current boot image on the cluster master if I need to go back to that image.
Q). Should I restart from scratch and reformat the cluster with an image recommended by this forum and I start testing from a known good stable place ?
(seems Armbian does not have anybody offering to test the RockPro64 4GB V 2.1 + PCIe NVME + BlueTooth\WiFi Module seeing as I have 10 of them I may be a good volunteer)
Or
Should I look at validating the current master Armbian packages and kernel driver installs to make sure there was not a corrupted installation / driver configuration issue that may lead to unearthing a genuine bug report?
-
On 4/1/2019 at 11:50 PM, chwe said:
Just another reminder: https://forum.armbian.com/guidelines
especially this points here:
.... post some logs etc etc
@chwe My bad .... to be fair ... every time I loaded the forum to post logs from the unit itself ... it chromium crashed the board :-)
I did not release that armbianmonitor posted to a urlupload site ... smart !
See attached to the results from armbianmonitor -u
-
On 4/1/2019 at 11:50 PM, chwe said:
what makes you sure the powering issues are gone? Did you check voltage on 5v rail after replacing the PSU under stress?
@chwe Yes I have been working with the Pico Cluster guys to revise the power supply unit they ship with their cluster and we have upgraded it to a 12v unit instead of a 5V unit. I have also completely rewired the power cable loom and installed a buck converter for the 5v Switches and Fans.
I have not gone to the extreme of checking individual output voltages and currents to the Boards from the PSU. But I have been monitoring the clusters total power consumption. The cluster is not loaded at all because I have not been able to do any work on it due to the stability of it. at peak it has never pulled in more than 64watts (5.3A). Most of the load is Cassandra recovering after the node reboots as its multi threaded it can load all 6 cores.
The 12v DC In goes via two Buck Converters (SY8113B) to create 2 x 5.1v rail. One of those rails goes into a RK808 Buck converter which I think is embedded into the RK3399 chip.
That RK808 feeds the GPIO pints which I have measured to be 5.190v.
There is a 4 Pin SATA JST Connector that says its wired to the raw DC in (12v) (but SATA also has 12v, 5v and 3,3v specifications so I am not sure of one of those pins is in addition the 5v rail direct after the SY8113B).
@chwe Do you want me to monitor the 5v rail after the SY8113B) with an Oscilloscope prior to lock up? Have you some concerns with with the board power design?



-
On 4/1/2019 at 11:50 PM, chwe said:
If I didn't miss something the Rockpro is still marked as wip in the downloadpage right?
but well, maybe we should rename it back to wip so that only expert=yes can build images for it.. to make it more obvious..
but also this sub-forum has a nice reminder:

My RockPi 4b was used in a pure CPU numbers crunshing project for 17 days between 75°C and 80°C without any crash.. Would I call the RockPi stable.. for sure not. It seems that it did well for this test but I've no idea if it runs stable under all the other use-cases people can imagine for the board in question.
Just another reminder: https://forum.armbian.com/guidelines
especially this points here:
what makes you sure the powering issues are gone? Did you check voltage on 5v rail after replacing the PSU under stress?
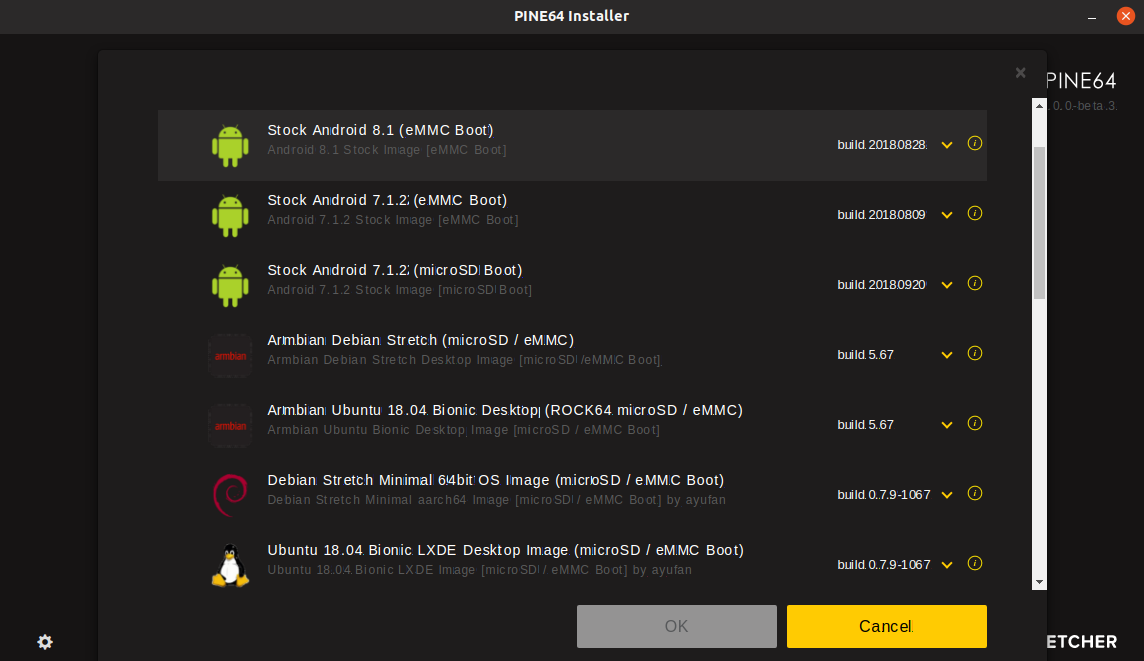
@chwe A quick heads up .... people may not be aware but the pine guys have their own image installer based on Etcher that automatically pulls the Armbian image down without any indication of WIP or Stable status of the project (see attached). This is here Pine falls down a bit ... they should have focus on one main desktop & command line release to recommend to users ... if they are going to obscure project status from their installer.
I only found out about WIP when I reported the issues.
I have been testing several desktop imaged and to be fair to Armbian ... they are all far away from where Ambian is on the RockPro64, its by far the best performing I have found (mrfixit build is broken atm if you have an emmc boot). Maybe this is just me but I only need a desktop when developing to access a web browser .... it to save me having to kill trees ...... I have had to print this lot all out so I could continue working because of the Chromium / Mali driver issue.
However I think that I have no choice but to reformat the whole cluster ... with all these lockups I have seen evidence of packages installed through apt that are actually missing libraries and I had to do force installs.
apt install --reinstall lightdm
apt install --reinstall libegli
if it was not an issue with the armbian package release at the time or if the 10 RockPro64's I have were HW Locking up and resetting during a package install.
Sometime its better to go back to square one, Whats peoples opinion ?
I am happy to act as a tester for this board and Armbian and find out where the real issues are.

-
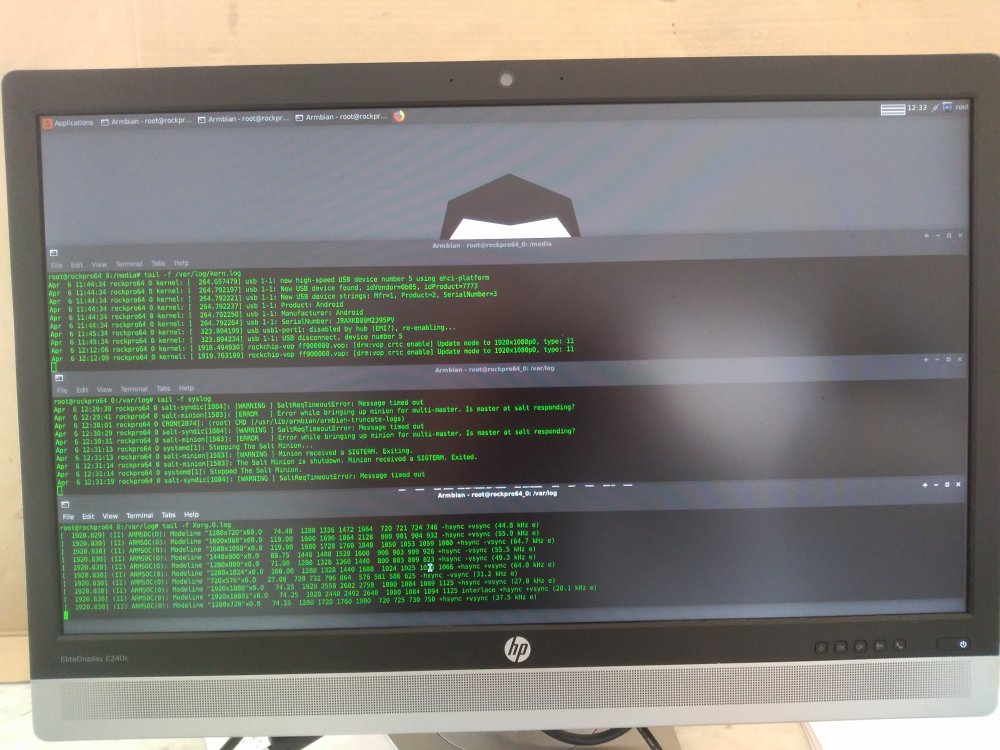
On 4/1/2019 at 2:11 PM, AndrewDB said:
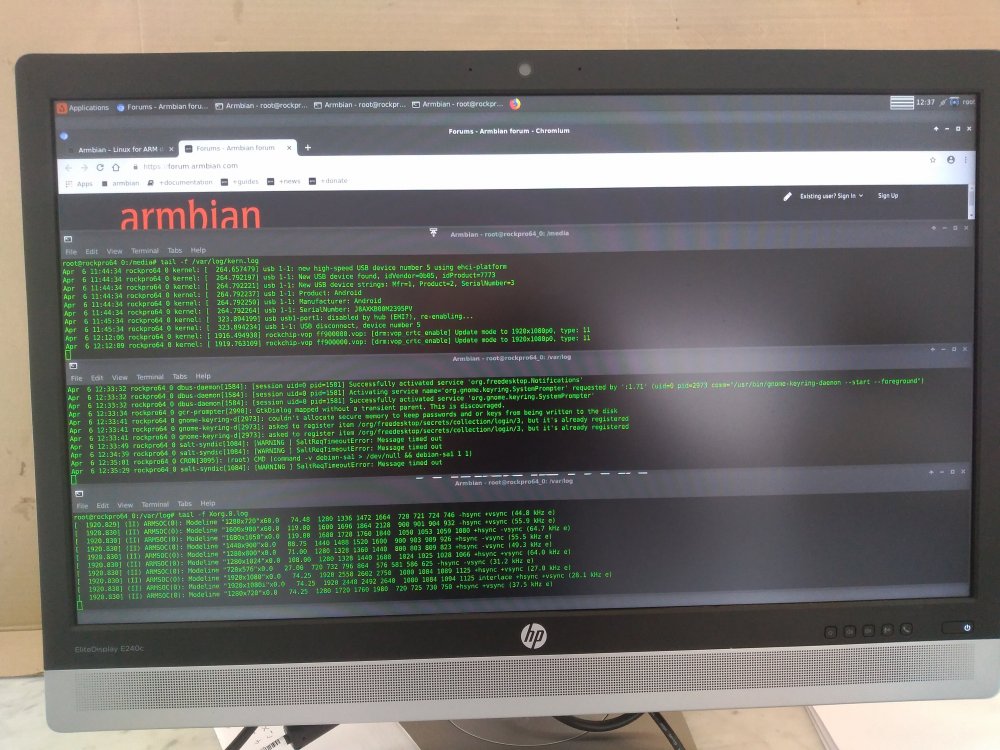
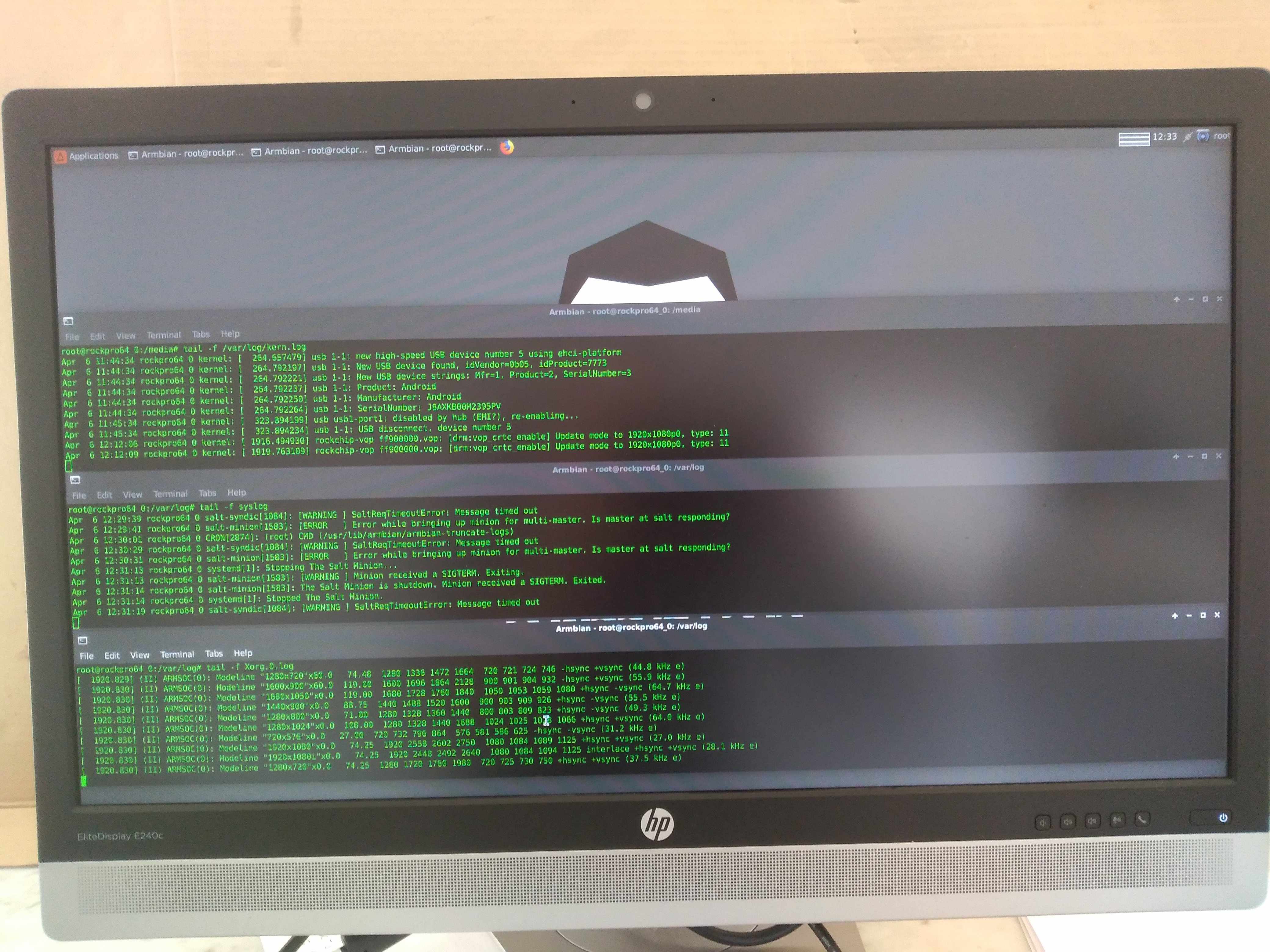
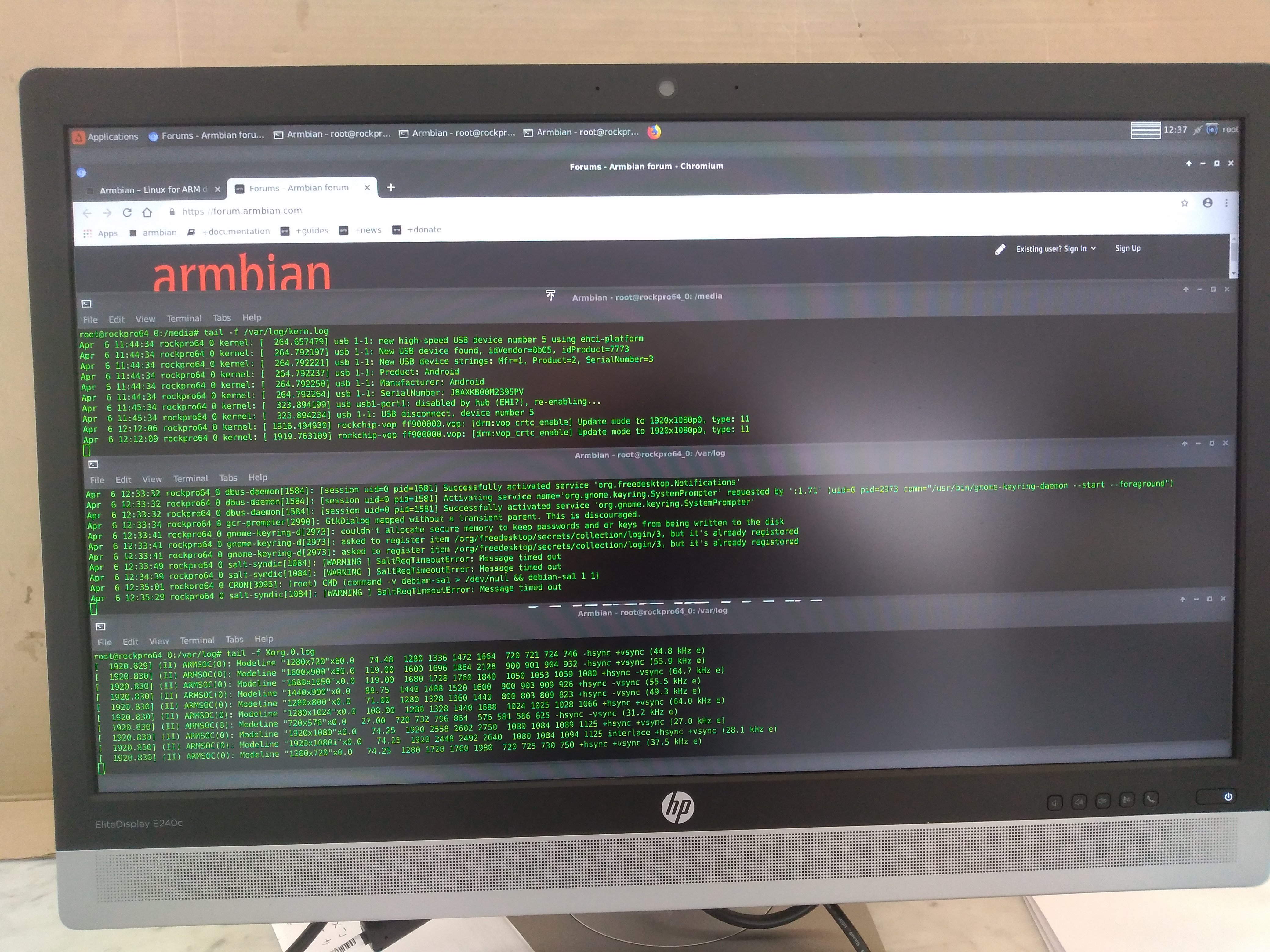
tail -f /var/log/{messages,kernel,dmesg,syslog}@AndrewDB Thanks for the suggestions I did try this but the lockup is so instantaneous. Nothing gets logged to disk .... see attached for a before and after screenshot of the syslog / kernel log and the X.org log ... this is why it has been so hard to troubleshoot. However somebody brilliant idea to launch chromium from a terminal has given me some interesting new lead's!
see attached before crash, after crash and teh chromium error to the command line when launched from a terminal;
I really don't care about chromium ,,,, when working on these boards I try to keep it as simple as possible and use stock packages in the hope I will have more bugs squashed. I am now using Firefox so I can at least start working on the GPIO code again.
Thanks for the suggestions.
It could be I need to run a debug kernel as I at least expected to see some issues there .... but the nature of the lockup could mean its a HW issue triggered in the Mali Graphics chip triggered by Chromium only
-
On 4/1/2019 at 1:26 PM, Da Alchemist said:
Using Rockpro64 for Desktop Scenarios is a really bad idea at this state of development.
@Da Alchemist that is a good point ... I made a rookie mistake thinking I could put up with a few glitches and still code. I then compounded it by using my cluster master as my development IDE, git master, salt master, Prometheus master, Grafana server.... its my own fault. I think its time to restart from scratch and move my code to github and reformat everything. I have clearly managed to bugger up the graphics mail drivers on the cluster Master/Dev box through continual upgrades and a link on the wiki to install HW accelerated mali drivers that are probably not feature complete.
The decision was in part due to the fact the pico cluster case only allows for one easy HDMI output and that was my cluster master.
I don't believe that there is thunderbolt support over USB C in the RockPor64 so a USB-C to HDMI Dongle is not an option.
I can reformat the cluster without desktop and I have a KVM so I can access a web browser and the cluster more easily and I can use vim (mostly I am writing C and python).
-
On 4/1/2019 at 1:09 AM, NicoD said:
@JMCCYou could run Chromium with the terminal (just type chromium)and see if it gives any clues to what's going on.
@NicoD Brilliant idea ..... I don't know why I did not think of that ...
See attached ... I got those errors when 1st launching the Chromium browser. It works for a while as I navigate to the Armbian forum ... then locks up with no more command line output. Interesting that it goes back to my hunch this was a graphics driver issue causing the instability. Its just strange that Chromium triggers the issue but not firefox!



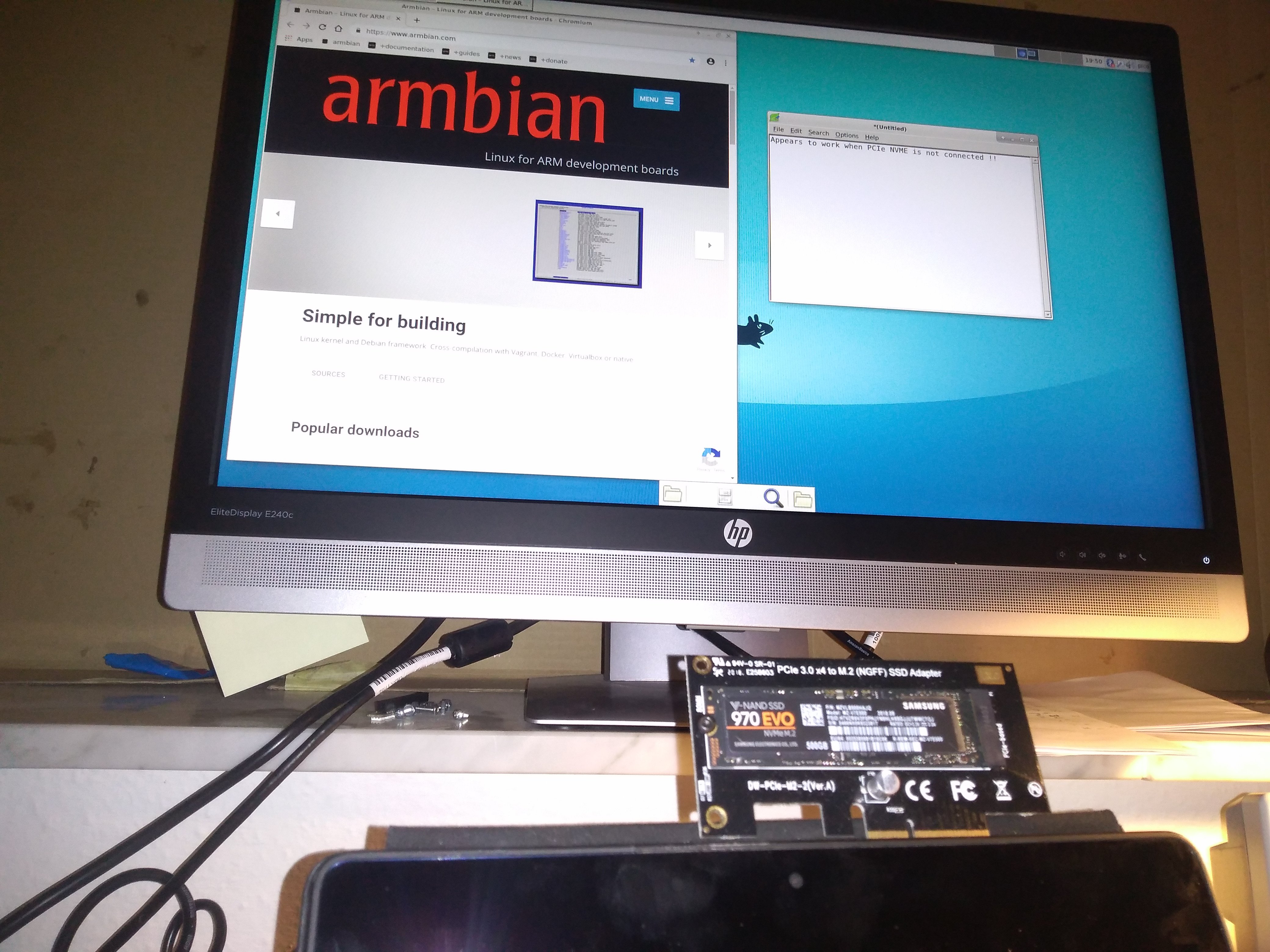
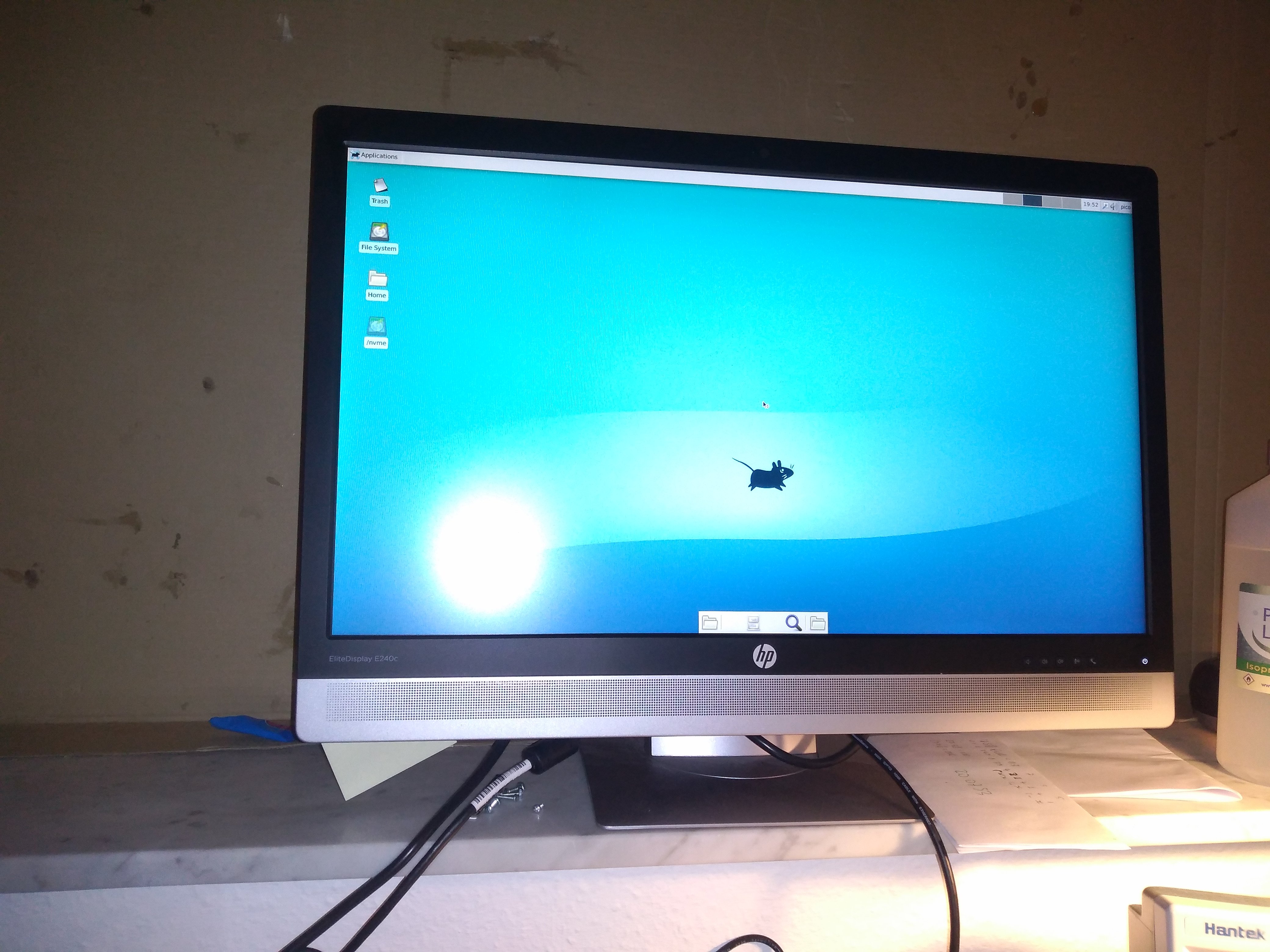






Rockpro64 will not boot
in Beginners
Posted
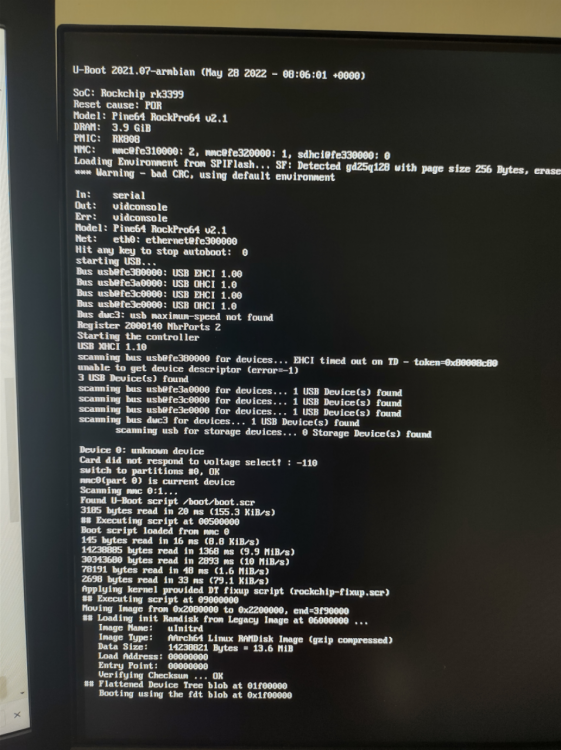
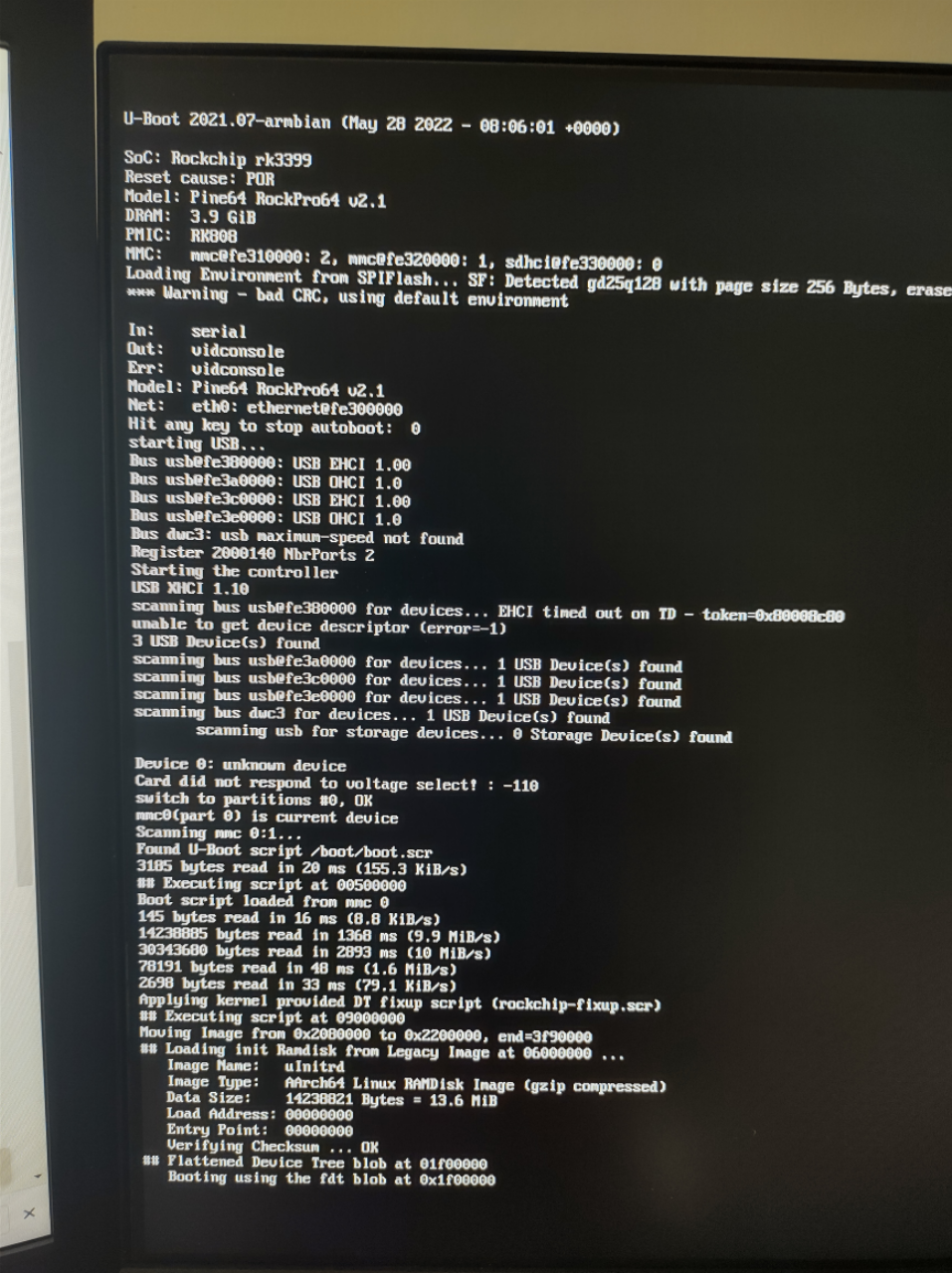
Update: well its was not the NVMe drive or the USB Peripherals. I disconnected them both and the Armbian image still refuses to boot the kernel
There is still and unknown device
Device 0: unknown device
Card did not respond to voltage select! : -110
switch to partitions #0, OK
and the image still fails to boot
Applying kernel provided DT fixup script (rockchip-fixup.scr)
## Executing script at 09000000
Moving Image from 0x2080000 to 0x2200000, end=3f90000
## Loading init Ramdisk from Legacy Image at 06000000 ...
Image Name: uInitrd
Image Type: AArch64 Linux RAMDisk Image (gzip compressed)
Data Size: 14238821 Bytes = 13.6 MiB
Load Address: 00000000
Entry Point: 00000000
Verifying Checksum ... OK
## Flattened Device Tree blob at 01f00000
Booting using the fdt blob at 0x1f00000