usual user
-
Posts
544 -
Joined
-
Last visited
Content Type
Forums
Store
Crowdfunding
Applications
Events
Raffles
Community Map
Everything posted by usual user
-

ffmpeg with hardware accelerated encoding
usual user replied to schunckt's topic in Software, Applications, Userspace
My rk3588 devices are e.g. exposing this: v4l2-compliance-odroid-m2.txt And here is the visualization of a video pipeline: video-pipeline.pdf Watch out for the v4l2slh265dec component. -
ffmpeg with hardware accelerated encoding
usual user replied to schunckt's topic in Software, Applications, Userspace
https://lore.kernel.org/linux-media/Z4e9wNxZjvnytXlL@pengutronix.de/ -
The mainline kernel has currently a shortcoming in USB-TYPEC support. FUKAUMI Naoki demonstrated a workaround for other devices that also works for the ODROID-M2.
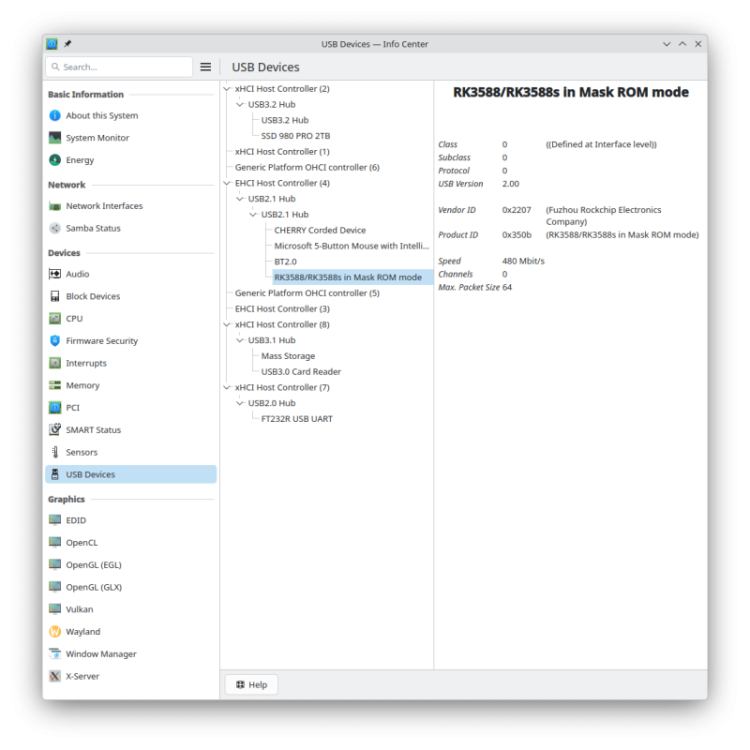
-
Armbian with preinstalled OpenMediaVault (OMV)
usual user replied to Igor's topic in Software, Applications, Userspace
Out of curiosity, does it work if you drop my firmware build in place? dd bs=512 seek=1 conv=notrunc,fsync if=u-boot-meson.bin of=/dev/${entire-device-to-be-used} u-boot-meson.bin.tgz -
A phandle is a magical number assigned during DTB assembly, whose value is irrelevant as long as it references the same node with the phandle property. The magic value can change when the structure changes because it is assigned arbitrarily; for example, by inserting an additional node.
-
In an XWindow environment, these are realistically expected numbers. In a Wayland environment, this is somewhat better; see glmark2-wayland-odroid-m1.log as a reference. But it is in no way comparable to a Mali G610; see glmark2-wayland-odroid-m2.log as a reference. Use WebGL Report to be sure.
-
Since you have now confirmed the HDMI functionality, the time has come for me to retire further support. I am only interested in generic support; for Armbian-specific issues, you'll have to wait for others who are interested.
-
Just out of curiosity, are you able to run your device with firmware loaded from microSD? I. e. firmware area on eMMC cleared. If so, you can try my kernel build and see how it works for you.
-
ODROID M1: dmesg | grep -i hdm [ 0.132185] /vop@fe040000: Fixed dependency cycle(s) with /hdmi@fe0a0000 [ 0.132325] /hdmi@fe0a0000: Fixed dependency cycle(s) with /vop@fe040000 [ 0.170085] /hdmi@fe0a0000: Fixed dependency cycle(s) with /hdmi-con [ 0.170254] /hdmi-con: Fixed dependency cycle(s) with /hdmi@fe0a0000 [ 1.180141] dwhdmi-rockchip fe0a0000.hdmi: Detected HDMI TX controller v2.11a with HDCP (DWC HDMI 2.0 TX PHY) [ 1.181147] dwhdmi-rockchip fe0a0000.hdmi: registered DesignWare HDMI I2C bus driver [ 1.182413] rockchip-drm display-subsystem: bound fe0a0000.hdmi (ops dw_hdmi_rockchip_ops) ODROID M2: dmesg | grep -i hdm [ 0.104853] /vop@fdd90000: Fixed dependency cycle(s) with /hdmi@fde80000 [ 0.104911] /hdmi@fde80000: Fixed dependency cycle(s) with /vop@fdd90000 [ 0.121323] /hdmi@fde80000: Fixed dependency cycle(s) with /hdmi-con [ 0.121364] /hdmi-con: Fixed dependency cycle(s) with /hdmi@fde80000 [ 0.547910] dwhdmiqp-rockchip fde80000.hdmi: registered DesignWare HDMI QP I2C bus driver [ 0.548835] rockchip-drm display-subsystem: bound fde80000.hdmi (ops dw_hdmi_qp_rockchip_ops) ODROID N2+: dmesg | grep -i hdm [ 0.079885] /soc/bus@ff600000/hdmi-tx@0: Fixed dependency cycle(s) with /soc/vpu@ff900000 [ 0.080281] /soc/vpu@ff900000: Fixed dependency cycle(s) with /soc/bus@ff600000/hdmi-tx@0 [ 0.080908] /soc/bus@ff600000/hdmi-tx@0: Fixed dependency cycle(s) with /soc/vpu@ff900000 [ 0.081352] /soc/bus@ff600000/hdmi-tx@0: Fixed dependency cycle(s) with /soc/vpu@ff900000 [ 0.090819] /soc/bus@ff600000/hdmi-tx@0: Fixed dependency cycle(s) with /soc/vpu@ff900000 [ 0.090892] /soc/vpu@ff900000: Fixed dependency cycle(s) with /soc/bus@ff600000/hdmi-tx@0 [ 0.097002] /soc/bus@ff600000/hdmi-tx@0: Fixed dependency cycle(s) with /hdmi-connector [ 0.097080] /hdmi-connector: Fixed dependency cycle(s) with /soc/bus@ff600000/hdmi-tx@0 [ 0.561480] meson-dw-hdmi ff600000.hdmi-tx: Detected HDMI TX controller v2.01a with HDCP (meson_dw_hdmi_phy) [ 0.561810] meson-dw-hdmi ff600000.hdmi-tx: registered DesignWare HDMI I2C bus driver [ 0.562112] meson-drm ff900000.vpu: bound ff600000.hdmi-tx (ops meson_dw_hdmi_ops) NanoPC-T6-LTS: dmesg | grep -i hdm [ 0.119431] /vop@fdd90000: Fixed dependency cycle(s) with /hdmi@fde80000 [ 0.119475] /hdmi@fde80000: Fixed dependency cycle(s) with /vop@fdd90000 [ 0.137536] /vop@fdd90000: Fixed dependency cycle(s) with /hdmi@fdea0000 [ 0.137589] /hdmi@fdea0000: Fixed dependency cycle(s) with /vop@fdd90000 [ 0.139716] /hdmi@fde80000: Fixed dependency cycle(s) with /hdmi0-con [ 0.139765] /hdmi0-con: Fixed dependency cycle(s) with /hdmi@fde80000 [ 0.139922] /hdmi@fdea0000: Fixed dependency cycle(s) with /hdmi1-con [ 0.139960] /hdmi1-con: Fixed dependency cycle(s) with /hdmi@fdea0000 [ 0.579865] dwhdmiqp-rockchip fde80000.hdmi: registered DesignWare HDMI QP I2C bus driver [ 0.580803] rockchip-drm display-subsystem: bound fde80000.hdmi (ops dw_hdmi_qp_rockchip_ops) [ 0.582184] dwhdmiqp-rockchip fdea0000.hdmi: registered DesignWare HDMI QP I2C bus driver [ 0.583115] rockchip-drm display-subsystem: bound fdea0000.hdmi (ops dw_hdmi_qp_rockchip_ops) At all HDMI ports work perfectly. And yes, they all use the same system booted from a USB enclosure. The only difference is the loaded DTB at system startup.
-
NanoPC-T6 - eMMC I/O errors under heavy load due to HS400 mode
usual user replied to KingJ's topic in Rockchip
Maybe another important data point to consider – are both of you running the same firmware? -
NanoPC-T6 - eMMC I/O errors under heavy load due to HS400 mode
usual user replied to KingJ's topic in Rockchip
That was just a simple one-liner (fdtoverlay -i rk3588-nanopc-t6.dtb -o rk3588-nanopc-t6.dtb rk3588-nanopc-t6-emmc.dtbo). In order to carry out the test in my environment, the typing task was a little more complex: It apparently depends on how the overlay was applied, because fundamentally it should also work when applied dynamically. However, the static application of an overlay has the disadvantage that in the case of an incompatibility, one is only confronted with an error message and does not experience a system that fails to start. It is not very difficult to get it out. It is held only by the slight adhesive strength of the thermal pad between the SoC and the casing when the bottom plate is removed. A cautious light steady pull releases it. The only difficulty is in gripping the board to make apply this pull. I screwed a bolt into one of the mounting PCB nuts and used it as a handle. With such a socket in one of the SMA antenna connection ports, the UART connection can be permanently routed to the outside without modifying the casing. I use it to route the fan connector outside. Without the possibility of providing meaningful serial console logs, you will probably be left on your own with it. -
NanoPC-T6 - eMMC I/O errors under heavy load due to HS400 mode
usual user replied to KingJ's topic in Rockchip
Admittedly, I had not tested the DTBO at runtime so far, but only applied it statically to the base DTB and checked whether all desired changes were made as intended. Now I am running my device with the applied overlay and I get the following: [ 0.940862] mmc0: new HS200 MMC card at address 0001 [ 0.941665] mmcblk0: mmc0:0001 A3A561 57.6 GiB [ 0.943039] mmcblk0: p1 p2 [ 0.943767] mmcblk0boot0: mmc0:0001 A3A561 4.00 MiB [ 0.945199] mmcblk0boot1: mmc0:0001 A3A561 4.00 MiB [ 0.946661] mmcblk0rpmb: mmc0:0001 A3A561 16.0 MiB, chardev (506:0) So everything is as expected, and yes, I have ensured that my system is running with the applied overlay. In the past, I have at least once noticed far too late that my system was running in a fallback, and a feature to be tested was not applied at all. That's just the disadvantage of a fail-safe system that only leaves a non-functional system in an extreme exceptional situation. Since you haven't provided meaningful logs, I can't say what is going wrong on your end. To rule out an error when applying the overlay, you could start your system with this DTB (rk3588-nanopc-t6.dtb) , which already contains the overlay applied statically. -
NanoPC-T6 - eMMC I/O errors under heavy load due to HS400 mode
usual user replied to KingJ's topic in Rockchip
You will certainly gain many grateful users whose devices are not equipped with an affected eMMC, but who still have to suffer from the slowdown nonetheless. Does the attached overlay work for you?rk3588-nanopc-t6-emmc.dtbo -
Oh, sorry, I didn't notice the non-existent 6 and read it as Helios64. Of course, my description of the boot method is not limited to Rockchip devices; it works on all for which a mainline U-Boot is available. I have used it on iMX6, LX2160A and S922X devices, but my remaining devices are all based on Rockchip. The solutions are too varied to present a turnkey solution here. However, I am sure that only a corresponding configuration for implementation is required to achieve the desired behavior, but for that, the U-Boot documentation must be consulted to decide which solution should be chosen.
-
Since the RK3399 U-Boot can use an HDMI display and a USB keyboard, I would simply configure a jumpstart option in the boot flow that mounts a different root filesystem. When booting, you just have to select this option. If interacting with the firmware console is too complicated, the recovery system can be placed on a removable storage device. In this way, in case of need, only the rescue media needs to be connected and the system restarted; no firmware console access is required. A completely firmware-controlled fallback mechanism is also possible, but it requires further special configuration of the firmware. Read this thread to understand what I mean by my statement.
-
Everything you wish for here is achievable with pure U-Boot technology. A long time ago, I tried to practice how to realize this here in the forum, but my lesson from it was: You can't teach old dogs new tricks, and Armbian users want to celebrate their cargo cult and hope that it will magically fulfill their wishes.
-
If I have not researched incorrectly, the Rock Pi S0 has microSD, USB, and Ethernet to access external storage, but you have not provided any information about which options are available in your specific case.
-
To replace an image on the eMMC, the MASKROM mode is not necessary. It is only required when the firmware is so damaged that it no longer works, but the signature is still intact and the MASKROM code still executes it. To replace an image, it is sufficient to boot from a rootfs that is not on the eMMC and replace it from there. And the good thing about it is that no device-specific hacks are necessary, just a properly configured bootflow. Furthermore, it is also self-contained, as no external devices with special software or other dependencies are necessary. It can also be automated in such a way that it runs unattended and the user only has to start the process initially.
-
Then you know which part you can contribute to mainline support, otherwise you have to use the manufacturer's BSP, because that's what you paid for.
-
https://lore.kernel.org/lkml/20240220-rk3568-vicap-v9-0-ace1e5cc4a82@collabora.com/
-
boot from nvme, install via armbian-install ?
usual user replied to H_Berger's topic in Orange Pi 5 Plus
IMHO this is a waste of money. In a device with NVME support, the advantages of an NVME SSD far outweigh those of an eMMC. The proprietary module interface also makes it difficult to use in other devices. And as a boot device for the firmware, it also offers no significant advantages over a microSD card. In any case, I would prefer a microSD card as a boot device, simply because of the easier handling when, for example, experimenting with the firmware. Only when everything works perfectly can one think about using an eMMC, but only if it is already permanently built into the device and the microSD card slot is to be kept free for other tasks. Only as long as there is no valid firmware signature in the SPI flash. Otherwise, firmware components will be loaded from there, and they may be able to load subsequent components (U-Boot) from other devices, but compatibility must be ensured. To avoid this, one must clean the SPI flash or store their own firmware in the SPI flash. However, since there is no way to fully test one's own firmware for functionality in advance, one may find oneself in a situation that requires a MASK-ROM recovery procedure. I prefer to trust the official documentation. -
Maybe my firmware build can replace Petitboot?
-
boot from nvme, install via armbian-install ?
usual user replied to H_Berger's topic in Orange Pi 5 Plus
Exactly Since I don't know the build, I can't make any concrete statements about it. It is also not possible under any circumstances, as the access procedures are far too complex to be meaningfully encoded in the MASK-ROM. As firmware devices, only SPI flash, MMC (eMMC, SD card), and USB with a proprietary protocol are available. This is correct. I just quickly built this version out of curiosity. I was just about to provide the binary artifacts when I quickly took a look at the schematic of your device. If I am not misinterpreting the schematic, your device only allows the fixed SPI-MMC-USB sequence and the forced immediate proprietary USB device. This means that you cannot execute the firmware completely from the microSD card, for example, if there is still a valid firmware signature in a device (SPI, eMMC) that is higher up in the priority list. It is therefore essential that you are familiar with the USB recovery procedure (MASK-ROM-MODE), in case something goes wrong during the firmware experiments with the higher prioritized devices (SPI, eMMC). -
boot from nvme, install via armbian-install ?
usual user replied to H_Berger's topic in Orange Pi 5 Plus
You are running with a broken firmware: Your version is also quite outdated: A current firmware log looks like this: -
Just out of curiosity, you are trying to play content that is encoded in AV1. Are you sure that your device is equipped with an AV1 decoder IP and that the kernel has the appropriate driver?