


tkaiser
-
Posts
5462 -
Joined
Content Type
Forums
Store
Crowdfunding
Applications
Events
Raffles
Community Map
Posts posted by tkaiser
-
-
Is this https://forum.openmediavault.org/index.php/Thread/24299 a known issue with 5.60?
In https://github.com/armbian/testings it's written that 'USB hot plugging' doesn't work which is something I'm fine with. But what does 'networking sometimes doesn't work' means exactly?
@Igor since I've seen you submitted the test report. What does that mean wrt networking? Isn't the next branch meant as a 'stable' branch where basic functionality has to work flawlessly? Did networking work prior to 5.60 release?
-
26 minutes ago, Werner said:
swappiness=0 http://ix.io/1nDr
swappiness=1 http://ix.io/1nDw
swappiness=60 http://ix.io/1nDCQuick summary:
- unfortunately all the time throttling happened so results are not comparable
- other than expected with vm.swappiness=1 less swap activity happened compared to vm.swappiness=0 (while 'everyone on the Internet' will tell you the opposite):
vm.swappiness=0 Compression: 2302,2234,2283 Decompression: 5486,5483,5490 Total: 3894,3858,3887 Write: 1168700 Read: 1337688 vm.swappiness=1 Compression: 2338,2260,2261 Decompression: 5506,5480,5512 Total: 3922,3870,3887 Write: 1138240 Read: 941548 vm.swappiness=60 Compression: 2266,2199,2204 Decompression: 5512,5495,5461 Total: 3889,3847,3832 Write: 1385560 Read: 1584220 vm.swappiness=100 Compression: 2261,2190,2200 Decompression: 5421,5485,5436 Total: 3841,3837,3818 Write: 1400808 Read: 1601404Still no idea why with with Orange Pi Plus and 1 GB RAM massive swapping occurs while the same benchmark on NanoPi Fire3 also with 1 GB results in low swapping attempts (different kernels, maybe different contents of /proc/sys/vm/*)
-
8 minutes ago, Werner said:
No idea what the io wait is causing
Haha, but now I know. I was an idiot before since it's simply zram/swap as can be easily seen by comparing iostat output from before and after:
before: zram1 0.93 3.69 0.01 1176 4 zram2 0.93 3.69 0.01 1176 4 zram3 0.93 3.69 0.01 1176 4 zram4 0.93 3.69 0.01 1176 4 after: zram1 588.13 1101.08 1251.45 1408792 1601184 zram2 586.62 1094.84 1251.62 1400808 1601404 zram3 582.01 1087.59 1240.44 1391524 1587092 zram4 587.14 1098.00 1250.54 1404848 1600016That's 5.3GB read and 6.1GB written on the zram devices. I still have no idea why this benchmark on some boards (most probably kernels) runs with 1 GB without swapping but not on others like here:
RAM size: 994 MB, # CPU hardware threads: 4 RAM usage: 882 MB, # Benchmark threads: 4NanoPi Fire3 also with just 1 GB RAM finishes with only minimal swapping:
RAM size: 990 MB, # CPU hardware threads: 8 RAM usage: 901 MB, # Benchmark threads: 8Maybe vm.swappiness is the culprit. Can you repeat the bench another three times doing the following prior to each run:
sysctl -w vm.swappiness=0 sysctl -w vm.swappiness=1 sysctl -w vm.swappiness=60 -
18 minutes ago, guidol said:
bringing the HDMI and Micro USB sockets to the same end as the USB & Ethernet!
Anyone catching the irony to keep Micro USB for powering? Guess it all depends on your target audience...
-
15 minutes ago, guidol said:
a "brother" for the NanoPi Fire3 which already has the S5P6818?
Please take a look at: http://wiki.friendlyarm.com/wiki/index.php/Main_Page#NanoPC.2FPi_Series
I would say the majority of boards is based on Samsung SoCs and there S5P6818 and (AFAIK pin compatible) S5P4418 (quad-A9) are the majority. They have several form factors and the majority of numbers at least has some meaning (3 being S5P6818 while 2 is S5P4418 with 'PC', 'NanoPi M' and 'Fire' -- now adding RK3399 to the mix as 4). With Allwinner boards so far the numbers they use have a different meaning.
I was only thinking about what could be in between a NEO Plus 2 and a NEO4 and since the software stack is already there and 3 would fit I thought about a S5P6818 variant. We shouldn't forget that FriendlyELEC deals not only with hobbyists like us but their boards get integrated into commercial devices so these customers might like to use same form factor and cooling attempts (SoC on same PCB side) but simply switch between SoCs based on use case.
Anyway: just wanted to point out that NEO4 is nothing entirely new with this form factor but there is at least some consistency (H5 based NEO Plus 2) and since FriendlyELEC is quite smart and cares about software support and compatibility maybe this will be the start of another 'series' that has not that much in common with the headless Allwinner NEO family. At least I would like to see a S5P6818 board with better passive heat dissipation (heatsinks on both Fire3 and NanoPC are too small IMO).
Well, back to NEO4... while thinking about S5P6818 and its limitations (especially IO) I again thought about what could be possible with PCIe here on this RK3399 tiny board. For example a dual Gigabit Ethernet HAT using an Intel 82576 or similar chips so we would get an ultra tiny router thingy with 3 fast Gigabit Ethernet adapters. I've seen @hjc is experimenting with several USB3 based Gigabit Ethernet chips connected to NanoPi M4 but switching to PCIe might improve latency here?
I mean we have PCIe standardized connectors on other RK3399 boards already. But M.2 on NanoPC-T4 won't work with anything else than a SSD without a bulky PCIe Extender, with RockPro64 or Rock960 EE board there's a full PCIe slot so everything is large. Currently those proprietary pin header PCIe implementations on NEO4 and NanoPi M4 combined with interesting HATs look quite appealing to me.
-
15 minutes ago, guidol said:
Welcome-Message did show 5.59
That's due to package 'linux-stretch-root-next-bananapim64' remaining at 5.59.
I don't understand this since years. The mechanism is broken, confuses users and generates unnecessary support requests. Why not fixing it or at least always update this package too with version bumps?
-
8 minutes ago, iamwithstupid said:
That HDMI Port could seem like an attempt to drive towards KIOSK / Mediaplayer
Well, it allows for a couple more use cases so why not. Adding the HDMI connector costs a lot of PCB space on such a tiny board but most probably increasing the BOM by just a few cents. Running headless Linux thingies is not the only use case in this world
")
@mindee said they got camera support working already in Linux so most probably this also applies to HW accelerated video decoding and then this little thing could be useful for a lot of scenarios.
-
9 minutes ago, iamwithstupid said:
NEO4 (like trying to make use of its fame)?
Same form factor and connector positions like NEO Plus 2, also same position of CPU on the bottom PCB side to ease heat dissipation with massive heatsink. Wonder whether we see an octa-core NEO3 with S5P6818 soon...
-
14 hours ago, sfx2000 said:
The VM params - most of them are tunable, can be done on the fly without a reboot - different use cases - desktop general vs. database server (yes, people can and do run databases on SBC's), each is going to have params that are more suitable for that particular application.
Thanks for the reminder. I totally forgot that running databases is amongst valid use cases. Based on my testings so far neither databases nor ZFS play very well with zram so the only reasonable vm.swappiness value with both use cases is IMO 0 (which means disable swap entirely starting with kernel 3.5 as far as I know, prior to that behavior at 0 was the same as 1 today) and using an appropriate amount of physical RAM for the use case or tune the application (calling ZFS an application too since default behavior to eat all available RAM except 1 GB for its own filesystem cache can be easily configured)
I added this to the release log right now.
Yesterday throughout the whole day I did some more testing even with those recommendations back from the days when we all did something horribly stupid: swapping to HDDs. I tested with vm.swappiness=10 and vm.vfs_cache_pressure=50 and got exactly same results as with both tunables set to 100 for the simple reason that the kernel limited the page cache in almost the same way with my workload (huge compile job). No differences in behavior, just slightly slower with reduced vm.swappiness.
So it depends on the use case, how situation with page cache looks like vs. application memory. But all numbers and explanations we find deal with swap on slow storage and/or are from 15 years ago. But today we're talking about something entirely different: no swap on ultra slow storage but compressing/decompressing memory on demand. Back in the old days with high swappiness of course you run into trouble once pages have to swapped back in from disk (switching to Chromium and waiting 20-40 seconds). But we're now talking about something entirely different. 'Aggressively swapping' with zram only is not high disk IO with slow storage any more but 'making better use of available memory' by compressing as much as least used pages as possible (again: what we have in Linux is way more primitive compared to e.g. Darwin/XNU).
And what really turns me down is this:
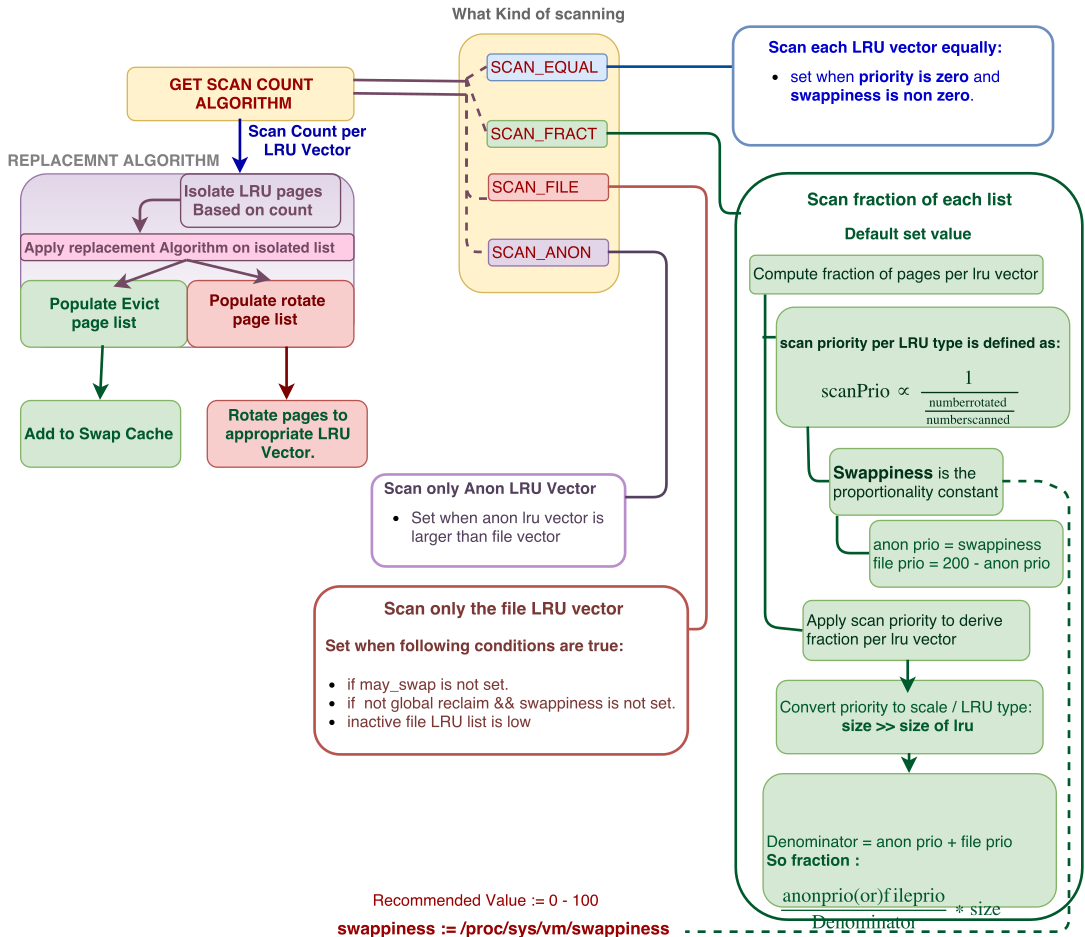
That's a oversimplified presentation of what's happening around swapping in Linux. And people now only focus on one single tunable they don't even understand for the sole reason they think it would be a percentage value (something that's not that complex as VM reality and something they're used to and feel they could handle) and feel it could be too 'aggressive' based on all the wrong babbling on the Internet about what vm.swappiness seems to be.
What everyone here is forgetting: with latest release we switched with vm.swappiness from '0' (no swap) to 'some number greater than 0' (swapping allowed). Of course this will affect installations and it might trigger bugs that got undetected for the simple reason that Armbian did not swap at all for the last years. So please can we now focus on what's important again and don't waste our time with feelings, believes and (mostly) wrong assumptions (not talking about you here).
-
10 minutes ago, adr3nal1n said:
Thanks for the tip regarding nmtui, I never knew this existed to be honest, as I have never really used NetworkManager as I do not run a desktop on any of my linux devices & servers, they all run headless and I manage them via ssh. I usually configure all my linux devices/servers with static IP addressing and if it is a debian based distro, then I set this via /etc/network/interfaces as suggested by the debian wiki
NM works great in CLI only mode and other distros than 'everything outdated as hell' (AKA Debian) use it for some time especially in server environments. If you don't need a desktop environment switching to Ubuntu Bionic might also be an idea (depends on what you're doing -- more recent package versions built with a more recent compiler sometimes result in stuff being done faster)
-
9 hours ago, adr3nal1n said:
Output is at http://ix.io/1nyf
Search for 'eth0: Link is Up' in there (doesn't appear for every boot since logging in Armbian is currently broken but nobody cares). The first occurrence shows only 100 MBits/sec negotiation w/o flow control and then no DHCP lease assigned. I would suspect cabling/contact problems on first boot 'magically' resolved later. There's no need to manually assign an IP address and please if you want to do so then keep the anachronistic /network/interfaces files blank and use nmtui instead.
That's the relevant log lines:
[ 13.398258] rk_gmac-dwmac ff540000.ethernet eth0: Link is Up - 100Mbps/Full - flow control off [ 7.441246] rk_gmac-dwmac ff540000.ethernet eth0: Link is Up - 1Gbps/Full - flow control rx/tx [ 7.207272] rk_gmac-dwmac ff540000.ethernet eth0: Link is Up - 1Gbps/Full - flow control rx/tx [ 15.023224] rk_gmac-dwmac ff540000.ethernet eth0: Link is Up - 1Gbps/Full - flow control rx/tx -
On 9/22/2018 at 2:34 PM, Moklev said:
Orange Pi Zero 512/v1.4 system log:
Do you use this board to boil water? 75°C SoC temperature reported at boot? I don't know how the thresholds are defined for 'emergency shutdown' but in this situation some more CPU activity alone can result in Armbian shutting down. If you want to diagnose a problem you need to diagnose it. Some problems arise over time. 'Worked fine for months and now unstable' happens for various reasons. Human beings usually then blame immediately the last change they remember (like upgrading the OS) instead of looking for the culprit.
Hopefully it still works but in your situation I would immediately install RPi-Monitor using
armbianmonitor -rYou get then a monitor instance running on your board and can look what happens and happened: https://www.cnx-software.com/2016/03/17/rpi-monitor-is-a-web-based-remote-monitor-for-arm-development-boards-such-as-raspberry-pi-and-orange-pi/
On 9/23/2018 at 4:55 PM, Moklev said:The good thing: reducing the value to 30 (vm.swappiness = 30) seems to solve the problem. Now I got ~22 h uptime without any hang...
Hahaha! I run a bunch of Ubuntu and Debian servers with lowered DRAM, huge memory overcommitment (300% and not just the laughable 50% as with Armbian defaults) and of course vm.swappiness set to 100. No problem whatsoever. If you think swapping is the culprit you need to monitor swap usage! At least your http://ix.io/1ngD output shows memory and swap usage that is not critical at all.
If you want to get the culprit whether this is related to swap you need to run something like 'iostat 600 >/root/iostat.log' and this in the background:
while true ; do echo -e "\n$(date)" >>/root/free.log free -m >>/root/free.log sleep 600 doneThen check these logs whether swapping happened. An alternative would be adjusting RPi-Monitor templates but while this is quite easy nobody will do this of course.
On 9/23/2018 at 4:55 PM, Moklev said:The bad one: an heavy zram usage on my AMD/Debian 9.5 microserver freeze the system (both gnome shell and ssh). :-|
I think zram has some problems with Debian...
Zram is a kernel thing and not related to any userland stuff at all. In other words: you have the same set of problems on a MicroServer and an ARM SBC running different software stacks? Are SBC and MicroServer connected to the same power outlet?
Unfortunately currently logging in Armbian is broken (shutdown logging and ramlog reported by @dmeey and @eejeel) but nobody cares (though @lanefu self assigned the Github issue). Great timing to adjust some memory related behavior and at the same time accepting that the relevant logging portions at shutdown that allow to see what's happening 'in the field' do not work any more)
-
21 minutes ago, ag123 said:
then there are other issues on the fringes, such as ssh failed to connect after some time
https://forum.armbian.com/topic/6751-next-major-upgrade-v560/?do=findComment&comment=62409
https://forum.armbian.com/topic/6751-next-major-upgrade-v560/?do=findComment&comment=62484
that seemed to be alleviated by setting a vm.swapiness, less than 100 leaving some room for some idle processes to simply 'stay in memory'
Ok, I give up. Do whatever f*ck you want with zram from now on in Armbian. I really can't stand it any more.
Let's do it like grandma already did it! That's the only way things work!
Why monitoring stuff? Why analyzing problems? Why doing some research? Assumptions, assumptions, assumptions! Nothing but assumptions!
-
22 minutes ago, chwe said:
I would be interested in a proper tool to determine the responsiveness in desktop scenarios with different swappiness settings, but until yet, I didn't found a way to do it.
This needs to be measured since 'feeling a difference' is always BS. I already referenced a perfect example: an Android app allowing silly things: https://www.guidingtech.com/60480/speed-up-rooted-android/
The author of at least the text clearly has not the slightest idea how VM (virtual memory) works in Linux, the whole thing is based on a bunch of totally wrong assumptions ('swap is bad', 'cleaning' memory, vm.swappiness being some sort of a percentage setting, Android developers being total morons since shipping their devices defaulting to 'very slow'). The icon showing a HDD already tells the whole sad story and the totally useless recommendation to reboot for this setting to take effect demonstrates what a bunch of BS this all is. And you'll find a a lot of people telling you their phone would be faster after they switched from 'Very slow' to 'Fast'). It's simple psychology.
Same with server migrations over the weekend that didn't happen for whatever reasons (missing prerequisites): On Monday users will report the server would be faster ('Really good job, guys!') and at the same time they will report that a printer in their department doesn't work any more (the one that has been replaced by another one already two weeks ago). Been there, experienced this too many times so that in the meantime we do not announce any server migrations any more.
If we're talking about expectations and efforts made human beings literally feel that something improved (it must have improved since otherwise no efforts would have been taken, true?). Same with 'change'. Change is evil so better let's stay with a somewhat undocumented default setting back from 15 years ago almost everybody does not understand. For the simple reason that it looked like a reasonable default to one or even a few kernel developers back at that time in combination with all the other VM tunables when swap was HORRIBLY EXPENSIVE since happening on ultra slow HDDs.
Talking about 'the other VM tunables': Why is no one talking about these guys but only about vm.swappiness?
root@nanopim4:~# ls -la /proc/sys/vm/ total 0 dr-xr-xr-x 1 root root 0 Sep 19 15:47 . dr-xr-xr-x 1 root root 0 Jan 18 2013 .. -rw-r--r-- 1 root root 0 Sep 25 11:55 admin_reserve_kbytes -rw-r--r-- 1 root root 0 Sep 25 11:55 block_dump --w------- 1 root root 0 Sep 25 11:55 compact_memory -rw-r--r-- 1 root root 0 Sep 25 11:55 compact_unevictable_allowed -rw-r--r-- 1 root root 0 Sep 25 11:55 dirty_background_bytes -rw-r--r-- 1 root root 0 Sep 25 11:55 dirty_background_ratio -rw-r--r-- 1 root root 0 Sep 25 11:55 dirty_bytes -rw-r--r-- 1 root root 0 Sep 25 11:55 dirty_expire_centisecs -rw-r--r-- 1 root root 0 Sep 25 11:55 dirty_ratio -rw-r--r-- 1 root root 0 Sep 25 11:55 dirtytime_expire_seconds -rw-r--r-- 1 root root 0 Sep 25 11:55 dirty_writeback_centisecs -rw-r--r-- 1 root root 0 Sep 25 11:55 drop_caches -rw-r--r-- 1 root root 0 Sep 25 11:55 extfrag_threshold -rw-r--r-- 1 root root 0 Sep 25 11:55 extra_free_kbytes -rw-r--r-- 1 root root 0 Sep 25 11:55 hugepages_treat_as_movable -rw-r--r-- 1 root root 0 Sep 25 11:55 hugetlb_shm_group -rw-r--r-- 1 root root 0 Sep 25 11:55 laptop_mode -rw-r--r-- 1 root root 0 Sep 25 11:55 legacy_va_layout -rw-r--r-- 1 root root 0 Sep 25 11:55 lowmem_reserve_ratio -rw-r--r-- 1 root root 0 Sep 25 11:55 max_map_count -rw-r--r-- 1 root root 0 Sep 25 11:55 min_free_kbytes -rw-r--r-- 1 root root 0 Sep 25 11:55 mmap_min_addr -rw------- 1 root root 0 Sep 25 11:55 mmap_rnd_bits -rw------- 1 root root 0 Sep 25 11:55 mmap_rnd_compat_bits -rw-r--r-- 1 root root 0 Sep 25 11:55 nr_hugepages -rw-r--r-- 1 root root 0 Sep 25 11:55 nr_overcommit_hugepages -r--r--r-- 1 root root 0 Sep 25 11:55 nr_pdflush_threads -rw-r--r-- 1 root root 0 Sep 25 11:55 oom_dump_tasks -rw-r--r-- 1 root root 0 Sep 25 11:55 oom_kill_allocating_task -rw-r--r-- 1 root root 0 Sep 25 11:55 overcommit_kbytes -rw-r--r-- 1 root root 0 Sep 19 15:47 overcommit_memory -rw-r--r-- 1 root root 0 Sep 25 11:55 overcommit_ratio -rw-r--r-- 1 root root 0 Sep 25 08:15 page-cluster -rw-r--r-- 1 root root 0 Sep 25 11:55 panic_on_oom -rw-r--r-- 1 root root 0 Sep 25 11:55 percpu_pagelist_fraction -rw-r--r-- 1 root root 0 Sep 25 11:55 stat_interval -rw-r--r-- 1 root root 0 Sep 25 06:31 swappiness -rw-r--r-- 1 root root 0 Sep 25 11:55 user_reserve_kbytes -rw-r--r-- 1 root root 0 Sep 24 15:58 vfs_cache_pressure -
9 minutes ago, chwe said:
I don't know how long @tkaiser let his OPi0 serve as a torrent server for armbian but I assume it was/is also micro USB powered
Powered via Micro USB from an USB port of the router next to it (somewhat recent Fritzbox). Storage was a 128 GB SD card, no peripherals, cpufreq settings limited the SoC to 1.1V (fixed 912 MHz) and so maximum consumption was predictable anyway (way below 3W). I could've allowed the SoC to clock up to 1.2GHz at 1.3V but performance with this specific use case (torrent server) was slightly better with fixed 912 MHz compared to letting the SoC switch between 240 MHz and 1200 MHz as usual.
I used one of my 20AWG rated Micro USB cables but honestly when it's known that the board won't exceed 3W anyway every Micro USB cable is sufficient.
-
BTW: Once we can collect some experiences with the new settings I have the following two tunables on my TODO list:
- vm.page-cluster (adjusting from HDD behavior to zram)
- vm.vfs_cache_pressure (playing with this based on use case)
But since we support more and more 64-bit boards the best method to better deal with available DRAM in low memory conditions would be using a 32-bit userland. But that's something literally no one is interested in or aware of.
-
5 hours ago, sfx2000 said:
Confused by your statement here
Ok, this is what you were explaining about vm.swappiness:
Quotethe 0-100 value in vm.swappiness is akin to the amount free memory in use before swapping is initiated - so a value of 60 says that as long as we have free memory of 60 percent, we don't swap, if less than that, we start swapping out pages
This is what the majority of 'people on the Internet' will also tell us (see here for a nice example which couldn't be more wrong). While someone else linking to the swap_tendency = mapped_ratio/2 + distress + vm_swappiness formula put it this way:
QuoteThe swappiness value is scaled in a way that confuses people. They see it has a range of 0-100 so they think of percent, when really the effective minimum is around 50.
60 roughly means don't swap until we reach about 80% memory usage, leaving 20% for cache and such. 50 means wait until we run out of memory. Lower values mean the same, but with increasing aggressiveness in trying to free memory by other means.
So given that vm.swappiness is mostly understood wrongly, especially is not what it seems to be (percentage of 'free memory' as you were explaining) and that the only reason to recommend vm.swappiness=60 seems to be just the usual 'Hey let's do it this way since... grandma already did it the same way' I think there is not that much reason to further continue this discussion on this basis especially given that there is zero productive contribution when dealing with such issues as 'making better use of available DRAM'.
We are still talking not about swapping out pages to ultra slow HDD storage but sending them to a compressed block device in RAM. There is NO disk access involved so why should we care about experiences from the past talking about spinning rust and 'bad real-world experiences' with high application latency. Everyone I know experimenting with zram in low memory situations ended up with setting vm.swappiness to the maximum.
Unless someone does some tests and is able to report differences between vm.swappiness=60 and 100 wrt 'application performance' there's no reason to change this. We want swapping to happen since in our case this is not ultra slow storage access but compressing memory (making better use of the amount of physical DRAM).
7 hours ago, sfx2000 said:Did you test with vm.swappiness set to 10
Of course not. We still want to make better use of RAM so swapping (compressing memory) is essentially what we want. If the value is really too high we'll know soon and can then adjust the value to whatever more appropriate value. But on the basis that vm.swappiness is simply misunderstood, the default is back from the days we swapped to spinning rust and today we want swapping to happen to free up RAM by compressing portions of it I see no further need to discuss this now.
If users report soon we'll see...
I had some hope you would come up with scenarios how to reasonably test for this stuff (you mentioned MariaDB)...
-
22 hours ago, sfx2000 said:
swap_tendency = mapped_ratio/2 + distress + vm_swappiness
(for the lay folks - the 0-100 value in vm.swappiness is akin to the amount free memory in use before swapping is initiated - so a value of 60 says that as long as we have free memory of 60 percent, we don't swap, if less than that, we start swapping out pages - it's a weighted value)
My understanding of vm.swappiness based on this and that is quite the opposite. It is not a percentage as explained here. My understanding is the whole relevance of vm.swappiness is dealing with swapping out application memory vs. dropping filesystem cache (influenced by setting vm.vfs_cache_pressure which defaults to 100). 'Everyone on the Internet' is telling you high vm.swappiness values favor high IO performance over app performance/latency. Every test I made so far tells a different story as long as 'zram only' is considered.
The tests I already did were with heavy memory overcommitment (running jobs that require 2.6 GB physical memory with just 1 GB RAM available). All the tests I did with lower swap activity also told me to increase vm.swappiness to the maximum possible (since apps finishing faster).
Another 4 hours spent on the following test:
Again compiling the ARM Compute Library. This time on a NanoPi M4 with 4 GB DRAM and kernel 4.4. First test with almost empty filesystem cache (no swapping happened at all even with vm.swappiness=100 -- just as expected):
real 31m54.478s user 184m16.189s sys 5m57.955sNext test after filling up filesystem caches/buffers to 2261 MB with vm.swappiness=100:
real 31m58.972s user 184m40.198s sys 5m58.623sNow the same with vm.swappiness=60 and again filling up caches/buffers up to 2262 MB:
real 32m1.119s user 184m28.312s sys 5m59.243sIn other words: light zram based swapping due to filesystem caches already somewhat filled with vm.swappiness=100 increased benchmark execution time by 4.5 seconds or ~0.2%. By switching to vm.swappiness=60 execution time increased by another 2.2 seconds (or ~0.1%). Rule of thumb when benchmarking: differences lower than 5% should be considered identical numbers.
So I still need a testing methodology that could convince me that a Linux kernel default setting made 15 years ago when we had neither intelligent use of DRAM (zram/zswap) nor fast storage (SSDs) but only horribly low performing spinning rust that is magnitudes slower than accessing DRAM makes any sense any more.
Background monitoring for vm.swappiness=100 and vm.swappiness=60. @Tido since I don't want to waste additional hours on this I hope you choose an appropriate testing methodology and monitoring when you provide insights why you feel vm.swappiness=100 being the wrong number.
Just for the record: while zram is a nice improvement I still consider the situation with Linux (or Android where zram originates from) horrible compared to other operating systems that make way better use of physical RAM. When I run any Mac with Linux I would need twice the amount of RAM compared to running the same hardware with macOS for example (most probably applies to Android vs. iOS as well prior to latest Android changes to finally make better use of RAM and allow the majority of Android devices to run somewhat smoothly with as less as 1 GB)
-
19 minutes ago, Werner said:
Should not have lots of background activity at all
Well, but that's what the extensive monitoring is for: to be able to throw results away quickly (no fire&forget benchmarking since only producing numbers without meaning).
The kernel reported high %sys and %io activity starting at the end of the single threaded 7-zip benchmark and that's the only reason your 7-zip numbers are lower than mine made on PineH64. Same H6, same type of memory, same u-boot, same kernel, same settings --> same performance.
IMO no more tests with improved cooling needed. The only remaining question is how good heat dissipation of both boards would be with otherwise identical environmental conditions (PineH64's PCB is rather huge and in both boards the copper ground plane is used as 'bottom heatsink' dissipating the heat away. But most probably PineH64 performs way better here with an appropriate heatsink due to larger PCB). But such a test is also pretty useless since results are somewhat predictable (larger PCB wins) and type of heatsink and whether there's some airflow around or not will be the more important factors. If heat dissipation problems are solved both boards will perform absolutely identical.
-
1 hour ago, Werner said:
Here are some results for the OrangePi One Plus (Allwinner H6), running 4.18.0-rc7 kernel. http://ix.io/1nr7
Exactly same numbers as PineH64 which is not that much of a surprise given same type of memory is used with same settings. Your 7-zip numbers seem to be lower but that's just some background activity trashing the benchmark as the monitoring reveals. If you see %sys and especially %iowait percentage in the monitoring output you know you need to repeat the benchmark and stop as many active processes as possible prior to benchmark execution:
System health while running 7-zip multi core benchmark: Time CPU load %cpu %sys %usr %nice %io %irq Temp 16:15:10: 1800MHz 5.63 23% 1% 18% 0% 3% 0% 25.0°C 16:15:31: 1800MHz 5.05 84% 1% 83% 0% 0% 0% 48.2°C 16:15:51: 1800MHz 4.77 86% 1% 84% 0% 0% 0% 43.1°C 16:16:31: 1800MHz 5.15 88% 15% 53% 0% 19% 0% 39.6°C 16:16:51: 1800MHz 4.94 80% 1% 78% 0% 0% 0% 42.7°C 16:17:11: 1800MHz 4.82 92% 1% 89% 0% 0% 0% 45.0°C 16:17:31: 1800MHz 4.64 87% 1% 85% 0% 0% 0% 41.9°C 16:17:52: 1800MHz 4.74 94% 16% 72% 0% 5% 0% 43.8°C 16:18:13: 1800MHz 4.69 81% 1% 80% 0% 0% 0% 48.6°C 16:18:33: 1800MHz 4.56 86% 1% 84% 0% 0% 0% 39.5°C 16:19:28: 1800MHz 6.93 84% 12% 38% 0% 34% 0% 31.2°CI bet unattended-upgrades was running in the background (you could check /var/log/dpkg.log)
-
Since it started here you should read the whole thread first:
-
1 hour ago, Tido said:
@tkaiser would have to put load (use RAM) on an SBC when doing the benchmarking
I started with this 'zram on SBC' journey more than 2 years ago, testing with GUI use cases on PineBook, searching for other use cases that require huge amounts of memory, testing with old as well as brand new kernel versions and ending up with huge compile jobs as an example where heavy DRAM overcommitment is possible and zram shows its strengths. Days of work, zero help/contributions by others until recently (see @botfap contribution in the other thread). Now that as an result of this work a new default is set additional time is needed to discuss about feelings and believes? Really impressive...
12 hours ago, sfx2000 said:putting a task to observe changes the behavior, as the task itself takes up time and resources
Care to elaborate what I did wrong when always running exactly the same set of 'monitoring' with each test (using a pretty lightweight 'iostat 1800' call which simply queries the kernel's counters and displays some numbers every 30 minutes)?
13 hours ago, sfx2000 said:it's ok to have different opinions here, and easy enough to test/modify/test again...
Why should opinions matter if there's no reasoning provided? I'm happy to learn how and what I could test/modify again since when starting with this zram journey and GUI apps I had no way to measure different settings since everything is just 'feeling' (with zram and massive overcommitment you can open 10 more browsers tabs without the system becoming unresponsive which is not news anyway but simply as expected). So I ended up with one huge compile job as worst case test scenario.
I'm happy to learn in which situations with zram only a vm.swappiness value higher than 60 results in lower performance or problems. We're talking about Armbian's new defaults: that's zram only without any other swap file mechanism on physical storage active. If users want to add additional swap space they're responsible for tuning their system on their own (and hopefully know about zswap which seems to me the way better alternative in such scenarios) so now it's really just about 'zram only'.
I'm not interested in 'everyone will tell you' stories or 'in theory this should happen' but real experiences. See the reason why we switched back to lzo as default also for zram even if everyone on the Internet tells you that would be stupid and lz4 always the better option.
-
7 hours ago, sfx2000 said:
trust the kernel, with 4.14, the numbers are honest
I don't get your conclusion. The kernel has no idea what's going on. Look at your own output: http://ix.io/1niD
You suffer from max real cpufreq being limited to 1200 MHz once the SoC temperature exceeds 60°C (you can 'fix' this by adding 'temp_soft_limit=70' to /boot/config.txt and then reboot to let ThreadX switch back to old behavior) and as soon as 80°C is exceeded fine grained throttling starts further decreasing real ARM clockspeeds while the kernel still reports running at 1400 MHz since the mailbox interface between kernel and ThreadX returns requested and not real values)
-
10 hours ago, mindee said:
Thanks for your suggestion, we made a SATA HAT prototype for NanoPi M4, it can connect with 4x 3.5inch hard drive and work well
Really looking forward to this HAT
BTW: I've not the slightest idea how much efforts and initial development costs are needed for such a HAT. But in case the Marvell based 4-port SATA solution will be somewhat expensive maybe designing another one with an ASMedia ASM1062 (PCIe x2 and 2 x SATA) and just one Molex for 2 drives might be an idea. Could be one design made for NEO4 that will work on M4 too with a larger (or dual-purpose) HAT PCB?
zram vs swap
in Armbian build framework
Posted
https://en.wikipedia.org/wiki/Swappiness
https://forum.armbian.com/topic/7819-sbc-bench/?do=findComment&comment=62802 (
Less swap activity with vm.swappiness=1 compared to vm.swappiness=0. So again, this is something that needs further investigation. We can not trust in stuff 'Everyone on the Internet' is telling (like lz4 being better than lzo since at least with ARM it's the other way around).